PHP网页抓取之抓取百度贴吧邮箱数据代码分享
百度贴吧大家都经常逛,去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发。
对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些回复的邮箱,然后再粘贴发送邮件,不是被折磨死就是被累死。无聊至极写了一个抓取百度贴吧邮箱数据的程序,需要的拿走。
程序实现了一键抓取帖子全部邮箱和分页抓取邮箱两个功能,界面懒得做了,效果如下:
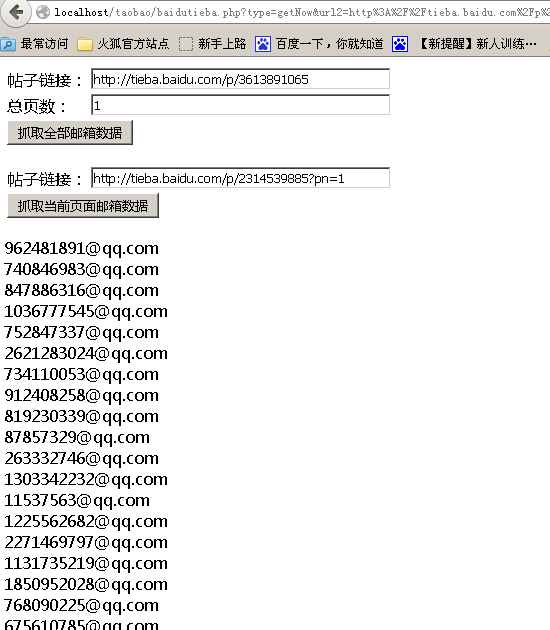
老规矩,直接贴源码
<?php
$url2="";
$page="";
if($_GET['url2']==""){
$url2="http://tieba.baidu.com/p/2314539885?pn=1";
}else{
$url2=$_GET['url2'];
}
if($_GET['page']==""){
$page="1";
}else{
$page=$_GET['page'];
}
?>
<form action="" method="get">
<input type="hidden" value="getAll" name="type" />
<table>
<tr>
<td>帖子链接:</td><td><input type="text" name="url" value="http://tieba.baidu.com/p/2314539885" style="width:300px;" /></td>
</tr>
<tr>
<td>总页数:</td><td><input type="text" name="page" style="width:300px;" value="<?php echo $page;?>" /></td>
</tr>
<tr>
<td colspan=2><input type="submit" value="抓取全部邮箱数据" /></td>
</tr>
</table>
</form>
<form action="" method="get">
<input type="hidden" value="getNow" name="type" />
<table>
<tr>
<td>帖子链接:</td><td><input type="text" name="url2" value="<?php echo $url2;?>" style="width:300px;" /></td>
</tr>
<tr>
<td colspan=2><input type="submit" value="抓取当前页面邮箱数据" /></td>
</tr>
</table>
</form>
<?php
if($_GET['type']!=""){
$counts=0;
if($_GET['type']=="getAll"){
$pages=$_GET['page'];
$url = $_GET['url'];
for($i=0;$i<$pages;$i++){
$ch2 = curl_init();
curl_setopt($ch2, CURLOPT_URL, $url);
curl_setopt($ch2, CURLOPT_FOLLOWLOCATION, TRUE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch2, CURLOPT_RETURNTRANSFER, TRUE);
$texts = curl_exec($ch2);
curl_close($ch2);
$dat=getEmail($texts);
for($j=0;$j<count($dat);$j++){
echo $dat[$j]."<br />";
$counts++;
}
}
}else if($_GET['type']=="getNow"){
$url = $_GET['url2'];
$ch2 = curl_init();
curl_setopt($ch2, CURLOPT_URL, $url);
curl_setopt($ch2, CURLOPT_FOLLOWLOCATION, TRUE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch2, CURLOPT_RETURNTRANSFER, TRUE);
$texts = curl_exec($ch2);
curl_close($ch2);
$dat=getEmail($texts);
for($i=0;$i<count($dat);$i++){
echo $dat[$i]."<br />";
$counts++;
}
}
echo '<h2>共采集到数据:'.$counts.'条</h2>';
}
function getEmail($str){
$pattern = "/([a-z0-9\-_\.]+@[a-z0-9]+\.[a-z0-9\-_\.]+)/";
preg_match_all($pattern,$str,$emailArr);
return $emailArr[0];
}
?>