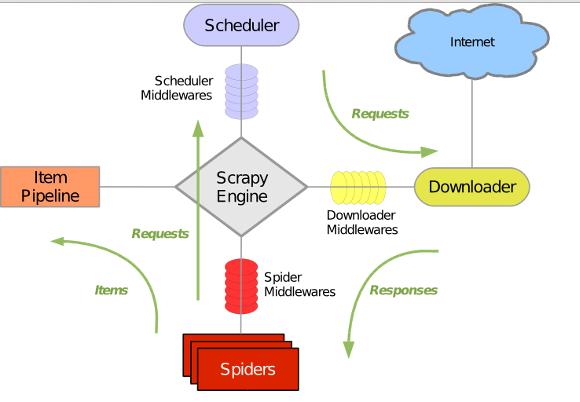
python并发爬虫实用工具tomorrow实用解析
tomorrow是我最近在用的一个爬虫利器,该模块属于第三方的一个模块,使用起来非常的方便,只需要用其中的threads方法作为装饰器去修饰一个普通的函数,既可以达到并发的效果,本篇将用实例来展示tomorrow的强大之处。后面将对tomorrow的实现原理做进一步的分析。
1.安装第三方包
pip install requests_html #网络请求包 pip install fake-useragent #获取useragent包 pip install tomorrow
2.普通下载方式
在这里我们用20个电影网址进行测试,并获取其标题,计算所用的时间
start=time.time()
for i in url_list:
print(get_xpath(get_req(i),"//title//text()"))
end=time.time()
print("普通方式花费时间",end-start)
get_req是我定义的访问网络的一个方法,get_xpath是为例使用xpath表达式获取其结果,这里是获取网址的标题。20个电影网址普通方式访问的结果在8-9秒之间。
3.使用tomorrow以后
start2 = time.time()
req_list = []
for url in url_list:
req = async_get_req(url)
req_list.append(req)
for req in req_list:
print(get_xpath(req, "//title//text()"))
end2 = time.time()
print("并发后花费时间", end2 - start2)
如果我们想要使用tomorrow,就要尽量减少耗时操作,访问网络并等待其回应就是一个非常耗时的工作,在这里我们需要做的是,并发的时候除了访问网络不要做其他操作,然后我们把获取的请求存一个列表,然后再去循环做其他操作,看不懂我说的没关系,直接看下面代码并尝试几次就明白了。
4.测试结果对比
来看程序的完整代码:
import time
from requests_html import HTMLSession
from fake_useragent import UserAgent as ua
from tomorrow import threads
headers = {"User-Agent": ua().Chrome}
session = HTMLSession()
url_list = ["https://movie.douban.com",
"http://www.1905.com/",
"http://www.mtime.com/",
"https://www.dy2018.com/",
"http://dytt8.net",
"https://www.piaohua.com/",
"http://maoyan.com",
"https://www.xigua110.com/",
"https://www.vmovier.com/",
"http://movie.kankan.com/",
"https://107cine.com/",
"http://movie.youku.com",
"http://film.qq.com",
"http://film.spider.com.cn",
"https://dianying.taobao.com/",
"http://www.wandafilm.com/",
"http://www.dygang.net/",
"http://www.bale.cn/",
"http://dianying.2345.com/",
"http://v.x2y4.com/"]
def get_req(url, timeout=10):
req = session.get(url, headers=headers, timeout=timeout)
if req.status_code == 200:
return req
@threads(5)
def async_get_req(url, timeout=10):
req = session.get(url, headers=headers, timeout=timeout)
if req.status_code == 200:
return req
def get_xpath(req, xpath_str):
return req.html.xpath(xpath_str)[0].strip().replace("\n", "")
start=time.time()
for i in url_list:
print(get_xpath(get_req(i),"//title//text()"))
end=time.time()
print("普通方式花费时间",end-start)
start2 = time.time()
req_list = []
for url in url_list:
req = async_get_req(url)
req_list.append(req)
for req in req_list:
print(get_xpath(req, "//title//text()"))
end2 = time.time()
print("并发后花费时间", end2 - start2)
运行三次上面的程序记录下每次的结果
第一次: 普通方式花费时间 7.883908271789551 并发后花费时间 2.2888755798339844 第二次: 普通方式花费时间 8.522203207015991 并发后花费时间 2.4674007892608643 第三次: 普通方式花费时间 9.062756061553955 并发后花费时间 2.8703203201293945
tomorrow使用起来很简单,在普通的函数上面加个threads装饰器即可以实现并发效果,括号中的数字是表示并发的次数,经过我的测试并不是并发次数越多越好,你需要选择一个中间点,因为还会受到网速的影响,我觉得一般并发数5-10就好.
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。