python3第三方爬虫库BeautifulSoup4安装教程
Python3安装第三方爬虫库BeautifulSoup4,供大家参考,具体内容如下
在做Python3爬虫练习时,从网上找到了一段代码如下:
#使用第三方库BeautifulSoup,用于从html或xml中提取数据 from bs4 import BeautifulSoup
自己实践后,发现出现了错误,如下所示:
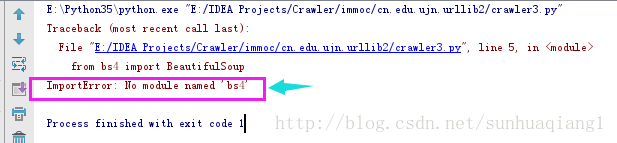
以上错误提示是说没有发现名为“bs4”的模块。即“bs4”模块未安装。
进入Python安装目录,以作者IDE为例,
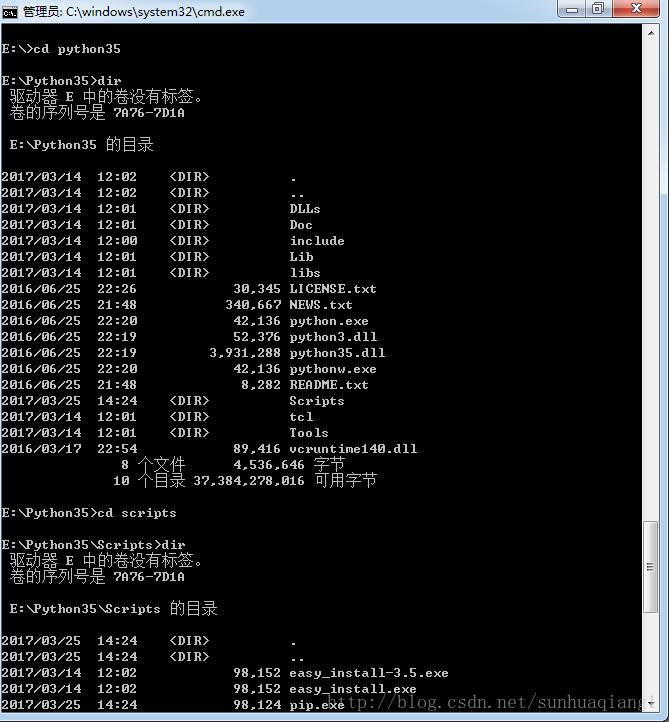
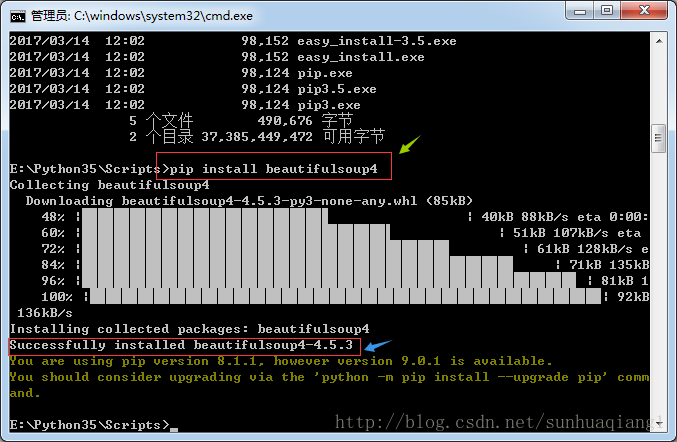
控制台提示第三方库BeautifulSoup4安装成功!回到之前的程序中,会发现IntelJ已经检测到第三方库BS4的安装,已自更新项目,此时项目恢复正常,无错误提示。
常见问题
在做BS4爬虫练习时,新建的文件名为bs4.py,结果出现如下错误提示:
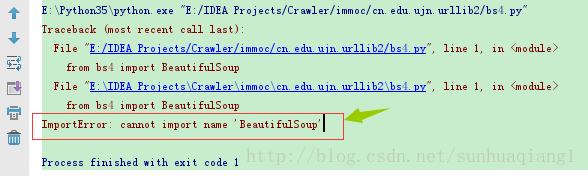
即ImportError: cannot import name BeautifulSoup一般有一下几种情况:
1. 在python2.x下安装的BeautifulSoup在python3.x下运行会报这种错,可用pip3 install Beautifulsoup4 .
2. 导入时指定bs4 像这样: from bs4 import BeautifulSoup.
3. 太巧合,如果你测试的文件名正好命名为bs4.py,那怎么整都会报这个错,把名字改成其他的吧。
附:BS4官方文档
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。

