python爬取51job中hr的邮箱
本文实例为大家分享了python爬取51job中hr的邮箱具体代码,供大家参考,具体内容如下
#encoding=utf8
import urllib2
import cookielib
import re
import lxml.html
from _ast import TryExcept
from warnings import catch_warnings
f = open('/root/Desktop/51-01.txt','a+')
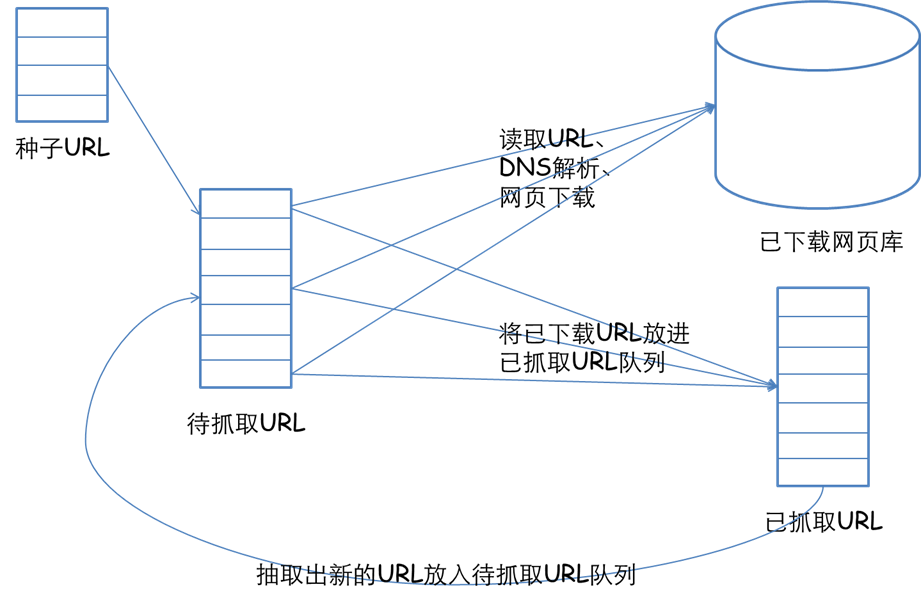
def read(city):
url = 'http://www.51job.com/'+city
cj = cookielib.MozillaCookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cookie_support)
opener.addheaders = [('User-agent','Mozilla/5.0 (X11; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0 Iceweasel/38.3.0')]
urllib2.install_opener(opener)
response = urllib2.urlopen(url)
http = response.read()
rex = 'http://jobs.51job.com/hot/.*?html'
value = re.findall(rex, http)
for i in value:
print i
try:
readpage(i)
except:
pass
def readpage(url):
cj = cookielib.MozillaCookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cookie_support)
opener.addheaders = [('User-agent','Mozilla/5.0 (X11; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0 Iceweasel/38.3.0')]
urllib2.install_opener(opener)
html = urllib2.urlopen(url,timeout = 2).read()
doc = lxml.html.fromstring(html)
rex = r'[\w\.-]+@(?:[A-Za-z0-9]+\.)+[A-Za-z]+'
results = doc.xpath('//div[@class="tmsg inbox"]/div[@class="con_msg"]/div[@class="in"]/p/text()')
for i in results:
xx = re.compile(rex)
for j in xx.findall(i):
print j
f.write(j+'\n')
f.flush()
if __name__ == '__main__':
city_list = ['zhangjiagang','zhanjiang','zhaoqing','zibo']
for i in city_list:
f.write(i+'\n')
f.flush()
try:
read(i)
except:
pass
f.flush()
f.close()
city_list大家自己整理一下,只能帮你们到这里了,谢谢大家的阅读,继续关注【听图阁-专注于Python设计】更多精彩内容。