解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点。最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码。看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病。这不,刚刚一解决就将这个方法公布与众,大家一同分享。
首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicode字符格式输出,会与系统编码格式不同,导致中文输出乱码,知道原因后我们就好解决了。下面上代码,实验对象仍是被人上了无数遍的百度主页~
# -*- coding: utf-8 -*-
import urllib2
import re
import requests
import sys
import urllib
#设置编码
reload(sys)
sys.setdefaultencoding('utf-8')
#获得系统编码格式
type = sys.getfilesystemencoding()
r = urllib.urlopen("http://www.baidu.com")
#将网页以utf-8格式解析然后转换为系统默认格式
a = r.read().decode('utf-8').encode(type)
print a
最后输出效果,中文完美输出
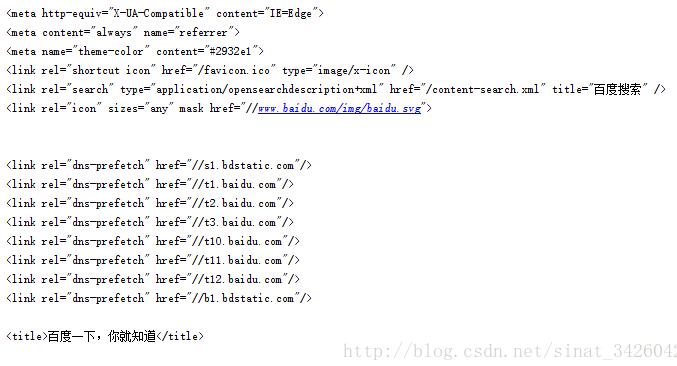
以上这篇解决Python网页爬虫之中文乱码问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。