python 动态迁移solr数据过程解析
前言
上项目的时候,遇见一次需求,需要把在线的 其中一个 collection 里面的数据迁移到另外一个collection下,于是就百度了看到好多文章,其中大部分都是使用导入的方法,没有找到在线数据的迁移方法。于是写了python脚本,分享出来。
思路: collection数据量比较大,所以一次性操作所有数据太大,于是分段执行操作。
先分段 按1000条数据量进行查询,处理成json数据
把处理后的json数据 发送到目的collection上即可
实现:
一、使用http的接口先进行查询
使用如下格式查询:
其中:collection_name 是你查询的collection的名称
rows 是需要查询多少行,这里设置为1000
start 从多少行开始进行查询,待会儿脚本里面就是控制这个参数进行循环查询
http://host:port/solr/collection_name/select?q=*:*&rows=1000&start=0
查询处理后会得到如下图片里面的数据格式,其中
在response里面,有两个键值数据是我们需要的,一个是numFound(总的数据条数),docs(所有json数据都在这里面)

在docs里面,每条数据都带有version 键值,这个需要给去掉

二、使用http的接口提交数据
wt:使用json格式提交
http://host:port/solr/collection_name/update?wt=json
header 需设置为 {"Content-Type": "application/json"}
提交参数:solr在做索引的时候,如果文档已经存在,就替换。(这里的参数也可以直接加到url里面)
{"overwrite":"true","commit":"true"}
data_dict 就是我们处理后的 docs数据
提交数据:data={"add":{ "doc":data_dict}}
三、实现的脚本如下:
#coding=utf-8
import requests as r
import json
import threading
import time
#发送数据到目的url des_url,data_dict 参数为去掉version键值后的一条字典数据
def send_data(des_url,data_dict):
data={"add":{ "doc":data_dict}}
headers = {"Content-Type": "application/json"}
params = {"boost":1.0,"overwrite":"true","&commitWithin":1000,"commit":"true"}
url = "%s/update?wt=json"%(des_url)
re = r.post(url,json = data,params=params,headers=headers)
if re.status_code != 200:
print("导入出错",data)
#获取数据,调用send_data 发送数据到目的url
def get_data(des_url,src_url):
#定义起始行
start = 0
#先获取到总的数据条数
se_data=r.get("%s/select?q=*:*&rows=0&start=%s"%(src_url,start)).text
se_dict = json.loads(se_data)
numFound = int(se_dict["response"]["numFound"])
#while循环,1000条数据为一个循环
while start < numFound:
#定义存放多线程的列表
th_li = []
#获取1000条数据
se_data=r.get("%s/select?q=*:*&rows=1000&start=%s"%(src_url,start)).text
#把获取的数据转换成字典
se_dict = json.loads(se_data)
#获取数据里的docs数据
s_data = (se_dict["response"]["docs"])
#循环得到的数据,删除 version键值,并使用多线程调用send_data 方法发送数据
for i in s_data:
del i["_version_"]
th = threading.Thread(target=send_data,args=(des_url,i))
th_li.append(th)
for t in th_li:
t.start()
t.join()
start += 1000
print(start)
if __name__ == "__main__":
#源数据,查询数据的collection地址
src_url = "http://ip:port/solr/src_connection"
#导入数据导目的collection 的地址
des_url = "http://ip:port/solr/des_connection"
start_time = time.time()
get_data(des_url,src_url)
end_time = time.time()
print("耗时:",end_time-start_time,"秒")
备注:
一、如果你的collection 不在同一个网络,不能实现在线传输,可以先把for循环 删除了version键值的数据,写入一个文件中,然后copy到目的网络的服务器上,循环读取文件进行上传,如下写入文件(这个就根据各位大佬的喜好来写了),但读取后,需要把每一条数据都转换成字典进行上传:
file = open("solr.json","a+")
for i in s_data:
del i["version"]
file.write(str(i)+"\n")
file.close()
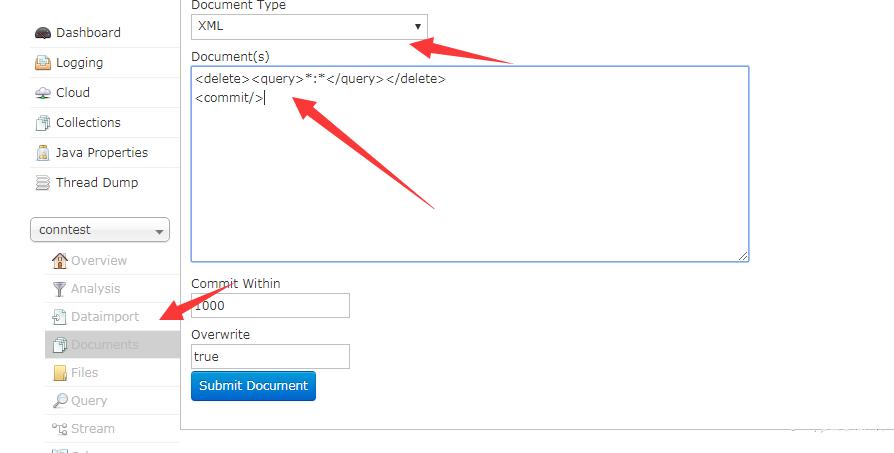
二、清除数据可使用一下方法,自测比较方便的一种
在你要清除collection里面
选择 documents
document type 选择xml
将一下内容复制到如图位置,最后点击submit document 按钮即可
#控制web界面删除数据 <delete><query>:</query></delete> <commit/>
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。