零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers
在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info / geturl
urlopen返回的应答对象response(或者HTTPError实例)有两个很有用的方法info()和geturl()
1.geturl():
这个返回获取的真实的URL,这个很有用,因为urlopen(或者opener对象使用的)或许会有重定向。获取的URL或许跟请求URL不同。
以人人中的一个超级链接为例,
我们建一个urllib2_test10.py来比较一下原始URL和重定向的链接:
from urllib2 import Request, urlopen, URLError, HTTPError
old_url = 'http://rrurl.cn/b1UZuP'
req = Request(old_url)
response = urlopen(req)
print 'Old url :' + old_url
print 'Real url :' + response.geturl()
运行之后可以看到真正的链接指向的网址:

2.info():
这个返回对象的字典对象,该字典描述了获取的页面情况。通常是服务器发送的特定头headers。目前是httplib.HTTPMessage 实例。
经典的headers包含"Content-length","Content-type",和其他内容。
我们建一个urllib2_test11.py来测试一下info的应用:
from urllib2 import Request, urlopen, URLError, HTTPError
old_url = 'http://www.baidu.com'
req = Request(old_url)
response = urlopen(req)
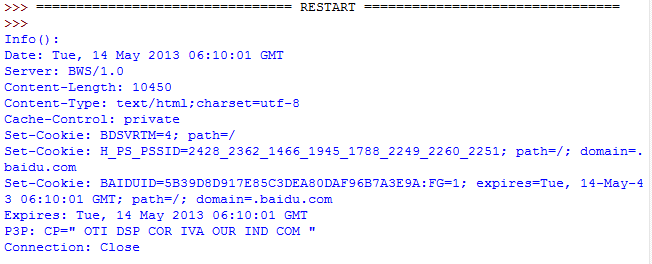
print 'Info():'
print response.info()
运行的结果如下,可以看到页面的相关信息:
下面来说一说urllib2中的两个重要概念:Openers和Handlers。
1.Openers:
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。
正常情况下,我们使用默认opener:通过urlopen。
但你能够创建个性的openers。
2.Handles:
Openers使用处理器handlers,所有的“繁重”工作由handlers处理。
每个handlers知道如何通过特定协议打开URLs,或者如何处理URL打开时的各个方面。
例如HTTP重定向或者HTTP cookies。
如果你希望用特定处理器获取URLs你会想创建一个openers,例如获取一个能处理cookie的opener,或者获取一个不重定向的opener。
要创建一个 opener,可以实例化一个OpenerDirector,
然后调用.add_handler(some_handler_instance)。
同样,可以使用build_opener,这是一个更加方便的函数,用来创建opener对象,他只需要一次函数调用。
build_opener默认添加几个处理器,但提供快捷的方法来添加或更新默认处理器。
其他的处理器handlers你或许会希望处理代理,验证,和其他常用但有点特殊的情况。
install_opener 用来创建(全局)默认opener。这个表示调用urlopen将使用你安装的opener。
Opener对象有一个open方法。
该方法可以像urlopen函数那样直接用来获取urls:通常不必调用install_opener,除了为了方便。
说完了上面两个内容,下面我们来看一下基本认证的内容,这里会用到上面提及的Opener和Handler。
Basic Authentication 基本验证
为了展示创建和安装一个handler,我们将使用HTTPBasicAuthHandler。
当需要基础验证时,服务器发送一个header(401错误码) 请求验证。这个指定了scheme 和一个‘realm',看起来像这样:Www-authenticate: SCHEME realm="REALM".
例如
Www-authenticate: Basic realm="cPanel Users"
客户端必须使用新的请求,并在请求头里包含正确的姓名和密码。
这是“基础验证”,为了简化这个过程,我们可以创建一个HTTPBasicAuthHandler的实例,并让opener使用这个handler就可以啦。
HTTPBasicAuthHandler使用一个密码管理的对象来处理URLs和realms来映射用户名和密码。
如果你知道realm(从服务器发送来的头里)是什么,你就能使用HTTPPasswordMgr。
通常人们不关心realm是什么。那样的话,就能用方便的HTTPPasswordMgrWithDefaultRealm。
这个将在你为URL指定一个默认的用户名和密码。
这将在你为特定realm提供一个其他组合时得到提供。
我们通过给realm参数指定None提供给add_password来指示这种情况。
最高层次的URL是第一个要求验证的URL。你传给.add_password()更深层次的URLs将同样合适。
说了这么多废话,下面来用一个例子演示一下上面说到的内容。
我们建一个urllib2_test12.py来测试一下info的应用:
# -*- coding: utf-8 -*-
import urllib2
# 创建一个密码管理者
password_mgr = urllib2.HTTPPasswordMgrWithDefaultRealm()
# 添加用户名和密码
top_level_url = "http://example.com/foo/"
# 如果知道 realm, 我们可以使用他代替 ``None``.
# password_mgr.add_password(None, top_level_url, username, password)
password_mgr.add_password(None, top_level_url,'why', '1223')
# 创建了一个新的handler
handler = urllib2.HTTPBasicAuthHandler(password_mgr)
# 创建 "opener" (OpenerDirector 实例)
opener = urllib2.build_opener(handler)
a_url = 'http://www.baidu.com/'
# 使用 opener 获取一个URL
opener.open(a_url)
# 安装 opener.
# 现在所有调用 urllib2.urlopen 将用我们的 opener.
urllib2.install_opener(opener)
注意:以上的例子我们仅仅提供我们的HHTPBasicAuthHandler给build_opener。
默认的openers有正常状况的handlers:ProxyHandler,UnknownHandler,HTTPHandler,HTTPDefaultErrorHandler, HTTPRedirectHandler,FTPHandler, FileHandler, HTTPErrorProcessor。
代码中的top_level_url 实际上可以是完整URL(包含"http:",以及主机名及可选的端口号)。
例如:http://example.com/。
也可以是一个“authority”(即主机名和可选的包含端口号)。
例如:“example.com” or “example.com:8080”。
后者包含了端口号。