Python网络爬虫项目:内容提取器的定义
1. 项目背景
在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作中。
2. 解决方案
为了解决这个问题,我们把影响通用性和工作效率的提取器隔离出来,描述了如下的数据处理流程图:
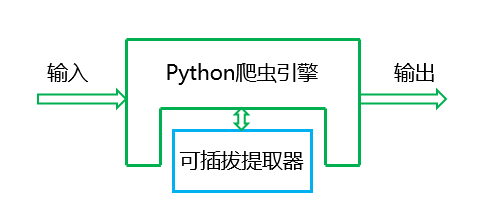
图中“可插拔提取器”必须很强的模块化,那么关键的接口有:
- 标准化的输入:以标准的HTML DOM对象为输入
- 标准化的内容提取:使用标准的xslt模板提取网页内容
- 标准化的输出:以标准的XML格式输出从网页上提取到的内容
- 明确的提取器插拔接口:提取器是一个明确定义的类,通过类方法与爬虫引擎模块交互
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义成一个类: gsExtractor
python源代码文件及其说明文档请从 github 下载
使用模式是这样的:
- 实例化一个gsExtractor对象
- 为这个对象设定xslt提取器,相当于把这个对象配置好(使用三类setXXX()方法)
- 把html dom输入给它,就能获得xml输出(使用extract()方法)
下面是这个gsExtractor类的源代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模块名: gooseeker
# 类名: gsExtractor
# Version: 2.0
# 说明: html内容提取器
# 功能: 使用xslt作为模板,快速提取HTML DOM中的内容。
# released by 集搜客(http://www.gooseeker.com) on May 18, 2016
# github: https://github.com/FullerHua/jisou/core/gooseeker.py
from urllib import request
from urllib.parse import quote
from lxml import etree
import time
class gsExtractor(object):
def _init_(self):
self.xslt = ""
# 从文件读取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , 'r' , encoding='UTF-8')
try:
self.xslt = file.read()
finally:
file.close()
# 从字符串获得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通过GooSeeker API接口获得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.gooseeker.com/api/getextractor?key="+ APIKey +"&theme="+quote(theme)
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回当前xslt
def getXslt(self):
return self.xslt
# 提取方法,入参是一个HTML DOM对象,返回是提取结果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
4. 用法示例
下面是一个示例程序,演示怎样使用gsExtractor类提取GooSeeker官网的bbs帖子列表。本示例有如下特征
- 提取器所用的xslt模板提前放在文件中:xslt_bbs.xml
- 仅作为示例,实际使用场景中,xslt来源有多个,最主流的来源是GooSeeker平台上的api
- 在控制台界面上打印出提取结果
下面是源代码,都可从 github 下载
#-*_coding:utf8-*-
# 使用gsExtractor类的示例程序
# 访问集搜客论坛,以xslt为模板提取论坛内容
# xslt保存在xslt_bbs.xml中
from urllib import request
from lxml import etree
from gooseeker import gsExtractor
# 访问并读取网页内容
url = "http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
# 生成xsltExtractor对象
bbsExtra = gsExtractor()
# 调用set方法设置xslt内容
bbsExtra.setXsltFromFile("xslt_bbs.xml")
# 调用extract方法提取所需内容
result = bbsExtra.extract(doc)
# 显示提取结果
print(str(result))
提取结果如下图所示:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。