利用python爬取软考试题之ip自动代理
前言
最近有个软件专业等级考试,以下简称软考,为了更好的复习备考,我打算抓取www.rkpass.cn网上的软考试题。
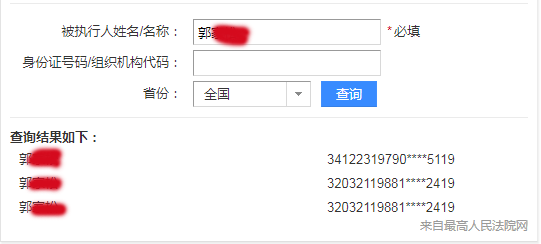
首先讲述一下我爬取软考试题的故(keng)事(shi)。现在我已经能自动抓取某一个模块的所有题目了,如下图:
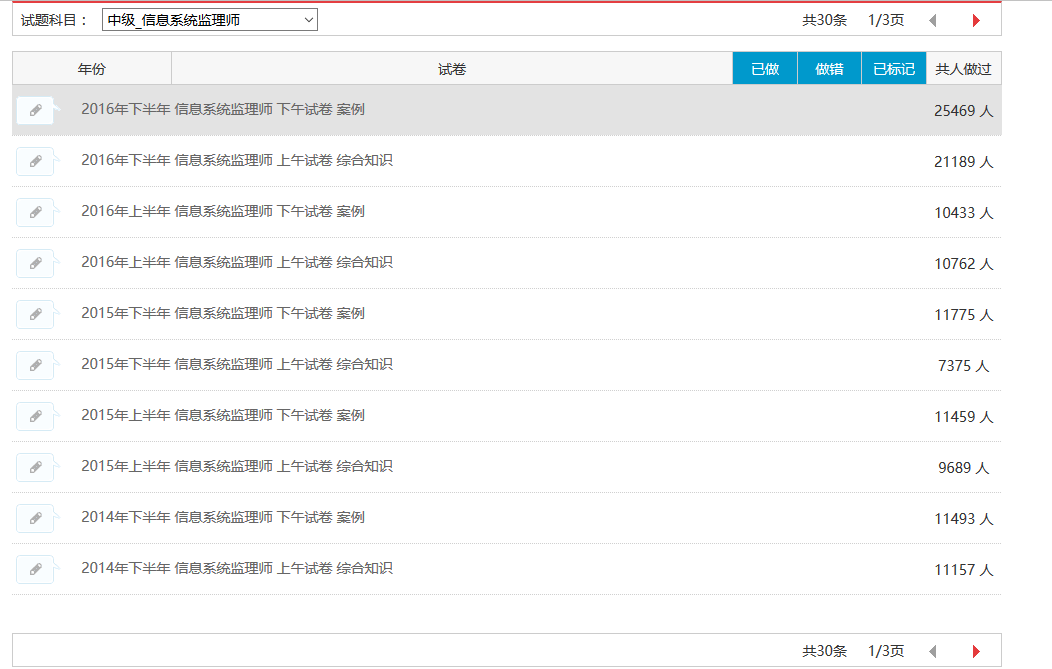
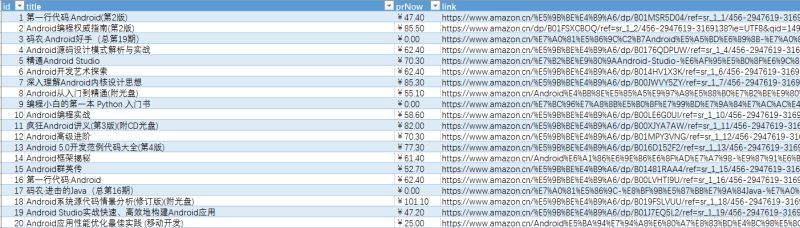
目前可以将信息系统监理师的30条试题记录全部抓取下来,结果如下图所示:
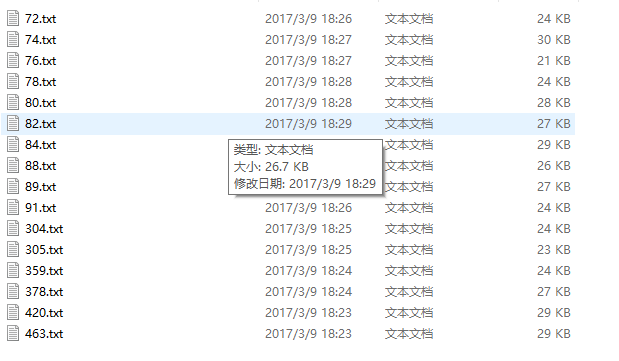
抓取下来的内容图片:

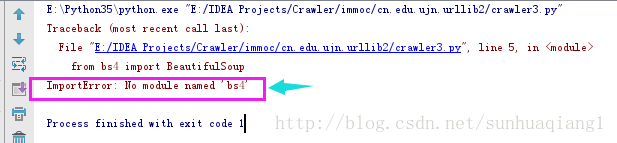
虽然可以将部分信息抓取下来,但是代码的质量并不高,以抓取信息系统监理师为例,因为目标明确,各项参数清晰,为了追求能在短时间内抓取到试卷信息,所以并没有做异常处理,昨天晚上填了很久的坑。
回到主题,今天写这篇博客,是因为又遇到新坑了。从文中标题我们可以猜出个大概,肯定是请求次数过多,所以ip被网站的反爬虫机制给封了。
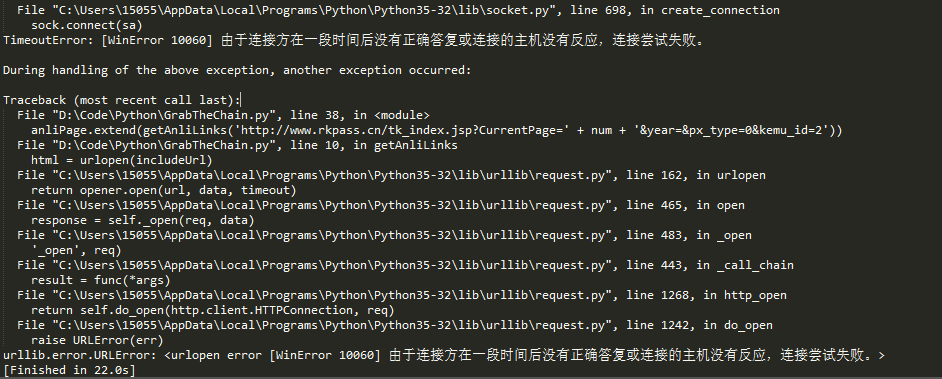
活人不能让尿憋死,革命先辈的事迹告诉我们,作为社会主义的接班人,我们不能屈服于困难,逢山开路,遇水搭桥,为了解决ip问题,ip代理这个思路就出来了。
在网络爬虫抓取信息的过程中,如果抓取频率高过了网站的设置阀值,将会被禁止访问。通常,网站的反爬虫机制都是依据IP来标识爬虫的。
于是在爬虫的开发者通常需要采取两种手段来解决这个问题:
1、放慢抓取速度,减小对于目标网站造成的压力。但是这样会减少单位时间类的抓取量。
2、第二种方法是通过设置代理IP等手段,突破反爬虫机制继续高频率抓取。但是这样需要多个稳定的代理IP。
话不多书,直接上代码:
# IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)
运行结果截图:
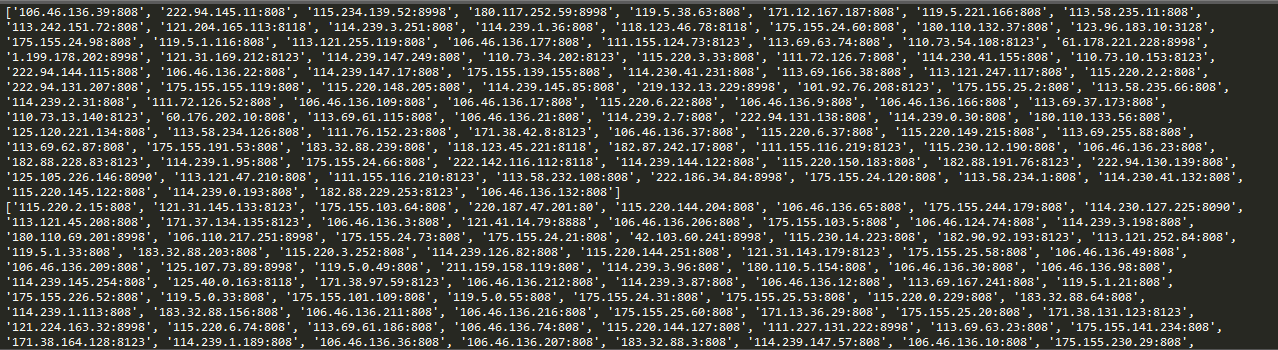
这样,在爬虫请求的时候,把请求ip设置为自动ip,就能有效的躲过反爬虫机制中简单的封锁固定ip这个手段。
-------------------------------------------------------------------------------------------------------------------------------------
为了网站的稳定,爬虫的速度大家还是控制下,毕竟站长也都不容易。本文测试只抓取了17页ip。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家学习或者使用python能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。