

相关文章
浅析Python3爬虫登录模拟
使用Python爬虫登录系统之后,能够实现的操作就多了很多,下面大致介绍下如何使用Python模拟登录。 我们都知道,在前端的加密验证,只要把将加密环境还原出来,便能够很轻易地登录。 首...
python爬虫之urllib,伪装,超时设置,异常处理的方法
Urllib 1. Urllib.request.urlopen().read().decode() 返回一个二进制的对象,对这个对象进行read()操作,可以得到一个包含网页的二进制字...
python制作花瓣网美女图片爬虫
花瓣图片的加载使用了延迟加载的技术,源代码只能下载20多张图片,修改后基本能下载所有的了,只是速度有点慢,后面再优化下 import urllib, urllib2, re, sys...
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值2...
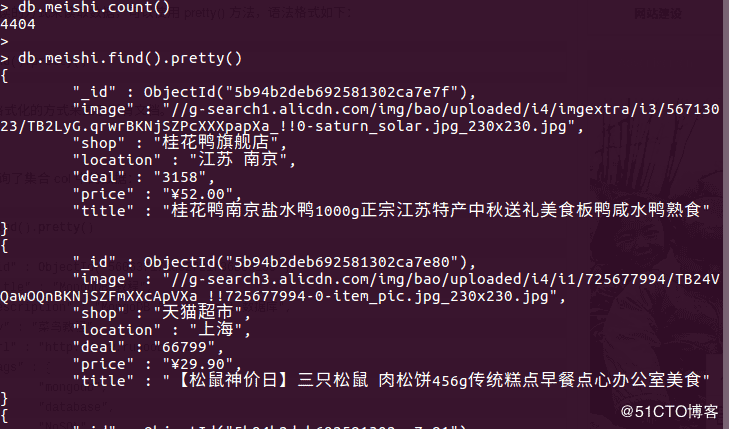
python3实现爬取淘宝美食代码分享
环境: ubuntu16.04 python3.5 python库: selenium, pyquery,pymongo, re 要求: 设置×××面浏览器访问,并将商品列表存入mo...