Python爬虫通过替换http request header来欺骗浏览器实现登录功能
以豆瓣为例,访问https://www.douban.com/contacts/list 来查看自己关注的人,要登录才能查看。
如果用requests.get()方法获取这个http,没登录只能抓取回一个登录界面,所以我们要用Python登录网站才能抓取想要的网页。
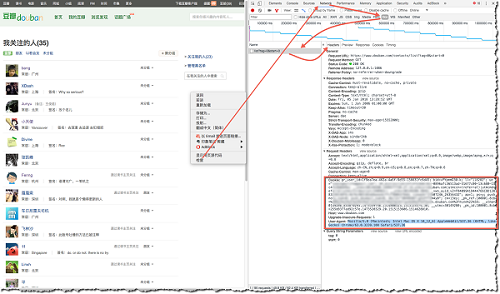
一个简便的方法就是自己在浏览器上登录好,然后通过下图方法(Chrome为例),找到自己的Cookie和User-Agent,然后发送request时用这复制来的header替换掉待发送的request以达到登录的目的,server端会凭这个认为你是已经登录的用户。
代码如下:
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
'Cookie':'gr_user_id=1f9ea7ea-462a-4a6f-9d55-156631fc6d45; bid=vPYpmmD30-k; ll="118282"; ue="codin; __utmz=30149280.1499577720.27.14.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/doulist/240962/; __utmv=30149280.3049; _vwo_uuid_v2=F04099A9dd; viewed="27607246_26356432"; ap=1; ps=y; push_noty_num=0; push_doumail_num=0; dbcl2="30496987:gZxPfTZW4y0"; ck=13ey; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1515153574%2C%22https%3A%2F%2Fbook.douban.com%2Fmine%22%5D; __utma=30149280.833870293.1473539740.1514800523.1515153574.50; __utmc=30149280; _pk_id.100001.8cb4=255d8377ad92c57e.1473520329.20.1515153606.1514628010.'
} #替换成自己的cookie
r = requests.get('https://www.douban.com/contacts/list', headers = headers)
print(r.text)
总结
以上所述是小编个大家介绍的Python爬虫通过替换http request header来欺骗浏览器实现登录 ,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!