python3爬虫之设计签名小程序
本文实例为大家分享了python3设计签名小程序的具体代码,供大家参考,具体内容如下
首先,上一下要做的效果图:
先是这样一个丑陋的界面(我尽力了的真的!)
然后随便输入名字
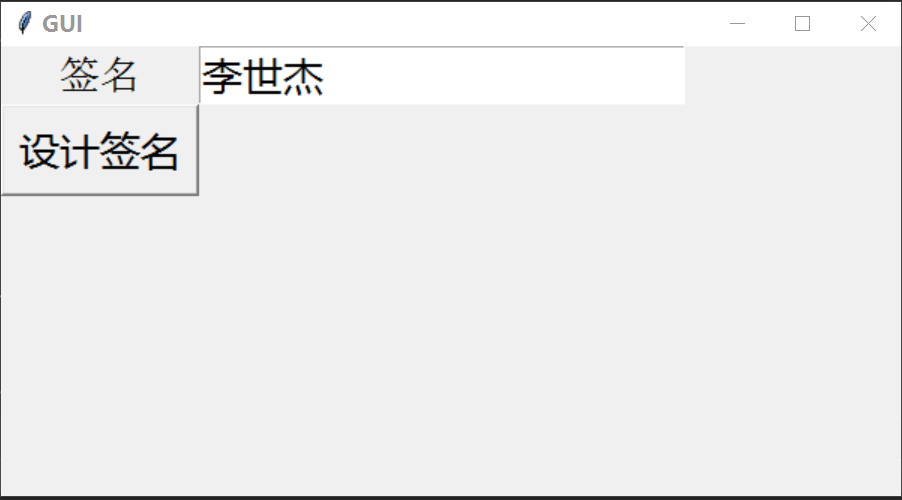
然后点击按钮会显示出对应的个性签名:

这个是怎么实现的呢?
其实这个是将一个签名网站http://www.uustv.com/的内容爬下来显示了而已:
源代码如下:
from tkinter import *
import requests
from tkinter import messagebox
import re
from PIL import Image,ImageTk
def download():
startUrl = 'http://www.uustv.com/'
name = entry.get()
if not name:
messagebox.showinfo('提示','请输入名字!')
else:
data = {
'word':name,
'sizes':'60',
'fonts':'jfcs.ttf',
'fontcolor':'#000000'
}
result = requests.post(startUrl,data = data)
result.encoding = 'utf-8'
req = '<div class="tu"><img src="(.*?)"/></div>'
imgUrl = startUrl+(re.findall(req,result.text)[0])
response = requests.get(imgUrl).content
with open('{}.gif'.format(name),'wb') as f:
f.write(response)
#im = Image.open('{}.gif'.format(name))
#im.show()
bm = ImageTk.PhotoImage(file = 'E:\py\{}.gif'.format(name))
label2 = Label(root, image = bm)
label2.bm = bm
label2.grid(row = 2,columnspan = 2)
root = Tk()
root.title('GUI')
root.geometry('600x300')
root.geometry('+500+200')
label = Label(root,text = '签名',font = ('华文行楷',20))
label.grid(row=0,column = 0)
entry = Entry(root,font = ('微软雅黑',20))
entry.grid(row = 0,column = 1)
Button(root,text = '设计签名',font = ('微软雅黑',20),command = download).grid(row = 1,column = 0)
root.mainloop()
关于图形界面GUI的操作之前博客已经说过了,主要就是三步:
1、root = Tk()
2、将标签和按钮等组件放进去
3、root.mainloop()
这里用的是requests去请求一个网页,post传入参数网址和data,data是怎么获取的呢?
打开浏览器,输入网址然后右键检查元素,点击网络,刷新页面删掉之前的记录,然后输入名字点击获取签名
然后得到页面如下:
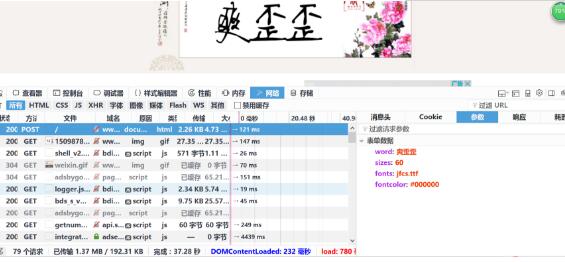
注意右边的参数即是我们需要的data,但是输入的名字一直是变得,其余三个是不会变的。
至于关于tkinter这些组件常用的有哪些,这里找到一篇好的博客供大家参考:tkinter模块常用参数(python3)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。