Python爬虫实现全国失信被执行人名单查询功能示例
本文实例讲述了Python爬虫实现全国失信被执行人名单查询功能。分享给大家供大家参考,具体如下:
一、需求说明
利用百度的接口,实现一个全国失信被执行人名单查询功能。输入姓名,查询是否在全国失信被执行人名单中。
二、python实现
版本1:
# -*- coding:utf-8*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
import requests
time1=time.time()
import pandas as pd
import json
iname=[]
icard=[]
def person_executed(name):
for i in range(0,30):
try:
url="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=6899" \
"&query=%E5%A4%B1%E4%BF%A1%E8%A2%AB%E6%89%A7%E8%A1%8C%E4%BA%BA%E5%90%8D%E5%8D%95" \
"&cardNum=&" \
"iname="+str(name)+ \
"&areaName=" \
"&pn="+str(i*10)+ \
"&rn=10" \
"&ie=utf-8&oe=utf-8&format=json"
html=requests.get(url).content
html_json=json.loads(html)
html_data=html_json['data']
for each in html_data:
k=each['result']
for each in k:
print each['iname'],each['cardNum']
iname.append(each['iname'])
icard.append(each['cardNum'])
except:
pass
if __name__ == '__main__':
name="郭**"
person_executed(name)
print len(iname)
#####################将数据组织成数据框###########################
data=pd.DataFrame({"name":iname,"IDCard":icard})
#################数据框去重####################################
data1=data.drop_duplicates()
print data1
print len(data1)
#########################写出数据到excel#########################################
pd.DataFrame.to_excel(data1,"F:\\iname_icard_query.xlsx",header=True,encoding='gbk',index=False)
time2=time.time()
print u'ok,爬虫结束!'
print u'总共耗时:'+str(time2-time1)+'s'
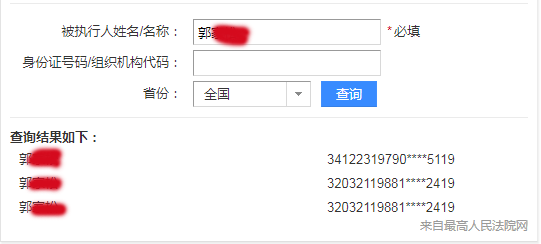
三、效果展示
"D:\Program Files\Python27\python.exe" D:/PycharmProjects/learn2017/全国失信被执行人查询.py
郭** 34122319790****5119
郭** 32032119881****2419
郭** 32032119881****2419
3
IDCard name
0 34122319790****5119 郭**
1 32032119881****2419 郭**
2
ok,爬虫结束!
总共耗时:7.72000002861s
Process finished with exit code 0
版本2:
# -*- coding:utf-8*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
import requests
time1=time.time()
import pandas as pd
import json
iname=[]
icard=[]
courtName=[]
areaName=[]
caseCode=[]
duty=[]
performance=[]
disruptTypeName=[]
publishDate=[]
def person_executed(name):
for i in range(0,30):
try:
url="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=6899" \
"&query=%E5%A4%B1%E4%BF%A1%E8%A2%AB%E6%89%A7%E8%A1%8C%E4%BA%BA%E5%90%8D%E5%8D%95" \
"&cardNum=&" \
"iname="+str(name)+ \
"&areaName=" \
"&pn="+str(i*10)+ \
"&rn=10" \
"&ie=utf-8&oe=utf-8&format=json"
html=requests.get(url).content
html_json=json.loads(html)
html_data=html_json['data']
for each in html_data:
k=each['result']
for each in k:
print each['iname'],each['cardNum'],each['courtName'],each['areaName'],each['caseCode'],each['duty'],each['performance'],each['disruptTypeName'],each['publishDate']
iname.append(each['iname'])
icard.append(each['cardNum'])
courtName.append(each['courtName'])
areaName.append(each['areaName'])
caseCode.append(each['caseCode'])
duty.append(each['duty'])
performance.append(each['performance'])
disruptTypeName.append(each['disruptTypeName'])
publishDate.append(each['publishDate'])
except:
pass
if __name__ == '__main__':
name="郭**"
person_executed(name)
print len(iname)
#####################将数据组织成数据框###########################
# data=pd.DataFrame({"name":iname,"IDCard":icard})
detail_data=pd.DataFrame({"name":iname,"IDCard":icard,"courtName":courtName,"areaName":areaName,"caseCode":caseCode,"duty":duty,"performance":performance,\
"disruptTypeName":disruptTypeName,"publishDate":publishDate})
#################数据框去重####################################
# data1=data.drop_duplicates()
# print data1
# print len(data1)
detail_data1=detail_data.drop_duplicates()
# print detail_data1
# print len(detail_data1)
#########################写出数据到excel#########################################
pd.DataFrame.to_excel(detail_data1,"F:\\iname_icard_query.xlsx",header=True,encoding='gbk',index=False)
time2=time.time()
print u'ok,爬虫结束!'
print u'总共耗时:'+str(time2-time1)+'s'
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。