Python爬虫设置代理IP(图文)
在爬虫的过程中,我们经常会遇见很多网站采取了防爬取技术,或者说因为自己采集网站信息的强度和采集速度太大,给对方服务器带去了太多的压力。
如果你一直用同一个代理ip爬取这个网页,很有可能ip会被禁止访问网页,所以基本上做爬虫的都躲不过去ip的问题。
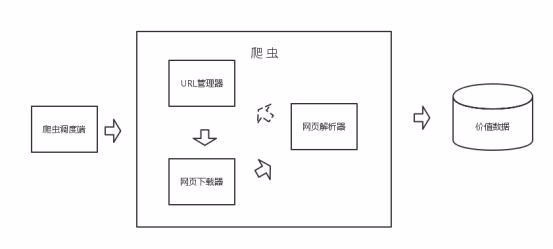
1、我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常爬取数据,一切看起来都是那么美好,然而不久之后可能会出现错误,比如 403 Forbidden,这时候你打开网页一看,可能会看到“您的 IP 访问频率太高”这样的提示。出现这种情况的原因是网站采取了一些反爬虫措施,比如,服务器会检测某个 IP 在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封 IP。
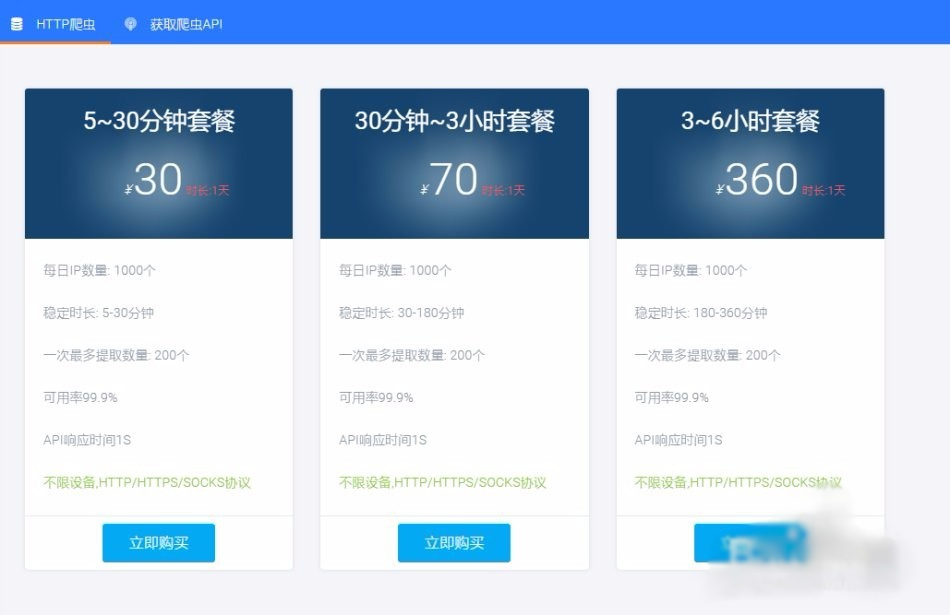
爬虫代理获取
获取IP池其实要找信的过的爬虫代理,我用的就是飞猪爬虫代理 ,优点自然就是使用率高于99%,缺点是没有免费的,0.03元一个IP,一天可以用1000个,一次可以API提取200个 。当然如果你们的用量还不满足可以加!

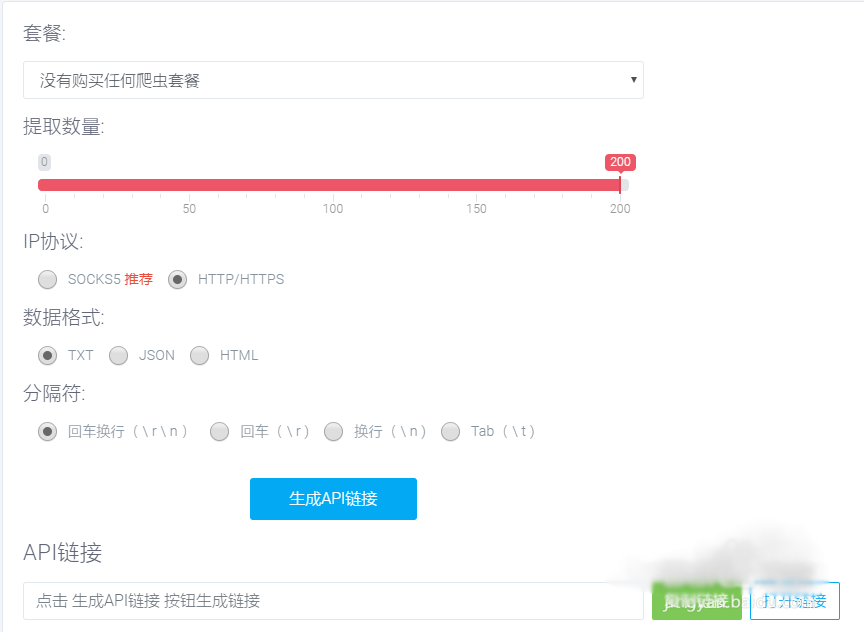
爬虫代理IP的使用
运行上面的代码会得到一个随机的proxies,把它直接传入requests的get方法中即可。


1、测试效果
本次测试得出的结论:飞猪IP爬虫代理,可用率、响应速度、稳定性、价格、安全性、使用频率,还是不错的,值得推荐
总结:以上就是关于python爬虫设置代理IP的步骤内容,感谢大家的阅读和对【听图阁-专注于Python设计】的支持。