相关文章
python并发爬虫实用工具tomorrow实用解析
tomorrow是我最近在用的一个爬虫利器,该模块属于第三方的一个模块,使用起来非常的方便,只需要用其中的threads方法作为装饰器去修饰一个普通的函数,既可以达到并发的效果,本篇将用...
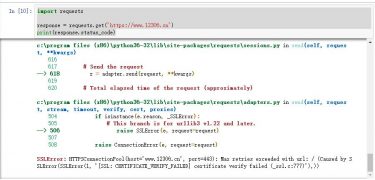
python中数据爬虫requests库使用方法详解
一、什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库。它urllib 更加方便,可以节约我们大...
python实现博客文章爬虫示例
复制代码 代码如下:#!/usr/bin/python#-*-coding:utf-8-*-# JCrawler# Author: Jam <810441377@qq.com>...
Python爬取网页中的图片(搜狗图片)详解
前言 最近几天,研究了一下一直很好奇的爬虫算法。这里写一下最近几天的点点心得。下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 ...

python多线程+代理池爬取天天基金网、股票数据过程解析
简介 提到爬虫,大部分人都会想到使用Scrapy工具,但是仅仅停留在会使用的阶段。为了增加对爬虫机制的理解,我们可以手动实现多线程的爬虫过程,同时,引入IP代理池进行基本的反爬操作。...