Python爬虫实现(伪)球迷速成
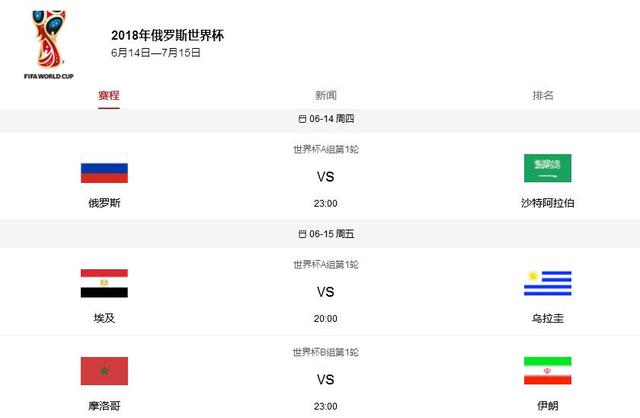
还有4天就世界杯了,作为一个资深(伪)球迷,必须要实时关注世界杯相关新闻,了解各个球队动态,这样才能在一堆球迷中如(大)鱼(吹)得(特)水(吹),迎接大家仰慕的目光!
给大家分享一个快速了解相关信息的办法:刷论坛!我们来一起做个虎扑论坛的爬虫吧!
抓包获取虎扑论坛相关帖子内容,逐条显示!
先来观察下网页,打开论坛首页,选择国际足球
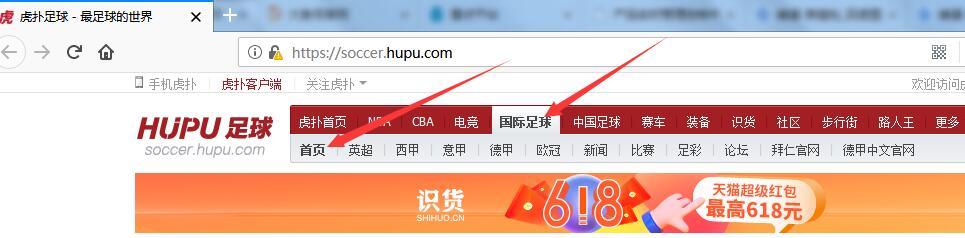
然后往下拉,找到世界杯相关内容
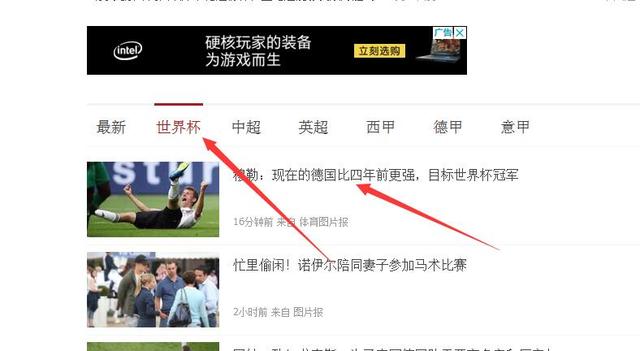
这里就是我们的目标了,所有相关的新闻都会在这里显示,用F12打开“开发者工具”然后往下浏览看看数据包
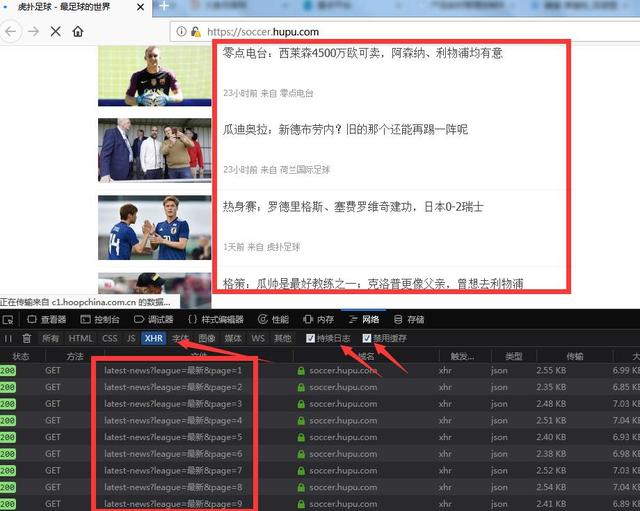
注意箭头指向的那几个地方!
这就是刚才浏览的新闻所在的json包,来看看具体数据是什么
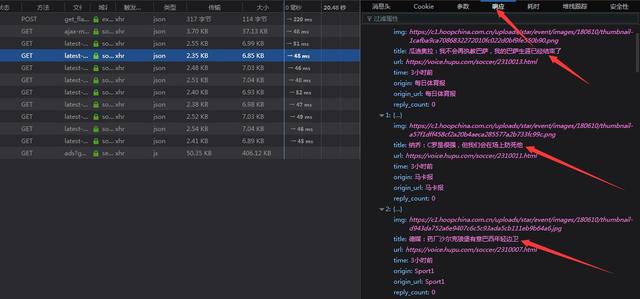
ok,标题、地址、发布时间包括来源都已经出现了!我们可以直接抓取json数据然后取出相关内容!
再进入具体新闻页面看看
世界杯快到了,看我用Python爬虫实现(伪)球迷速成!
所有的文本内容,都在<div class="artical-main-content">这个标签下的<p></p>标签内,我们可以用xpath直接取div下的所有文本内容!
这里就不一 一说明了,直接上代码,并录个小的GIF图片给大家看看效果
#Q群542110741
# -*- coding:utf-8 -*-
import requests
from lxml import etree
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Host':'soccer.hupu.com',
'Referer':'https://soccer.hupu.com/'}
i = 0
while 1:
#构建循环页面翻页
url = 'https://soccer.hupu.com/home/latest-news?league=世界杯&page='
i += 1
#获取json数据,一页20个
html = requests.get(url+str(i),headers=header).json()['result']
for info in html:
time_r = info['time']#发布时间
title = info['title']#标题
url_r = info['url']#新闻链接
origin = info['origin']#来源
print(title)
print('发布时间:',time_r,' '*5,'来自:',origin)
head = header
head['Host'] = 'voice.hupu.com'#更改header中Host参数
html_r = requests.get(url_r,headers=head)#获取新闻详情
html_r.encoding = 'utf-8'#编码格式指定
#获取div下的所有文本
datas = etree.HTML(html_r.text).xpath('//div[@class="artical-content-read"]')[0].xpath('string(.)').strip()
print('\n'+'内容:'+'\n'*2,datas,'\n')
#可由用户手动退出循环
if input('任意键继续,“q”退出') in ['q', 'Q']:
exit()
总结
以上所述是小编给大家介绍的Python爬虫实现(伪)球迷速成,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!