python构建基础的爬虫教学
爬虫具有域名切换、信息收集以及信息存储功能。
这里讲述如何构建基础的爬虫架构。
1、urllib库:包含从网络请求数据、处理cookie、改变请求头和用户处理元数据的函数。是python标准库.urlopen用于打开读取一个从网络获取的远程对象。能轻松读取HTML文件、图像文件及其他文件流。
2、beautifulsoup库:通过定位HTML标签格式化和组织复杂的网络信息,用python对象展现XML结构信息。不是标准库,可用pip安装。常用的对象是BeautifulSoup对象。
1、基础爬虫
爬虫需要首先import对象,然后打开网址,使用BeautifulSoup对网页内容进行读取。

2、使用print输出打开的网址的内容。
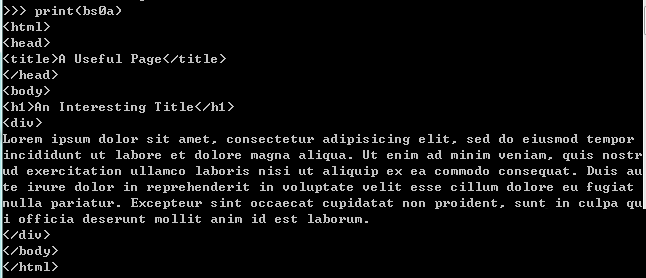
3、从输出中可以看出内容的结构为:

4、输出内容中的html-body-h1的内容可使用四种语句。
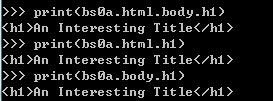

5、BeautifulSoup可提取HTML、XML文件的任意节点的信息,只需要目标信息旁边或附近有标记。
1、Error在运行代码时,经常会出现错误,看懂错误出现的原因才能解决存在的问题。
2、在html=urlopen('')中会发生两种错误:网页在服务器上不存在或服务器不存在。
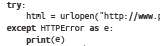
3、网页在服务器上不存在会出现HTTPError,可使用try语句进行处理。
当程序返回HTTPError错误代码时,会显示错误内容。
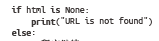
4、服务器不存在时,urlopen会返回None.
可使用判断语句进行检测。
调用的标签不存在会出现None,调用不存在的标签下的子标签,就会出现AttributeError错误。
总结:以上就是关于python构建基础的爬虫的基础步骤内容,感谢大家的阅读和对【听图阁-专注于Python设计】的支持。