50行Python代码获取高考志愿信息的实现方法
最近遇到个任务,需要将高考志愿信息保存成Excel表格,BOSS丢给我一个网址表格之后就让我自己干了。虽然我以前也学习过Python编写爬虫的知识,不过时间长了忘了,于是摸索了一天之后终于完成了任务。不得不说,Python干这个还是挺容易的,最后写完一看代码,只用了50行就完成了任务。

准备工作
首先明确一下任务。首先我们要从网址表格中读取到一大串网址,然后访问每个网址,获取到页面上的学校信息,然后将它们在写到另一个Excel中。显然,我们需要一个爬虫库和一个Excel库来帮助我们完成任务。
第一步自然是安装它们,requests-html是一个非常好用的HTML解析库,拿来做简单的爬虫非常优雅;而openpyxl是一个Excel表格库,可以轻松创建和处理Excel数据。
pip install requests-html openpyxl
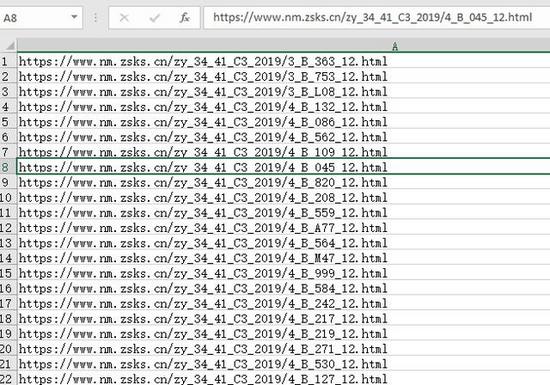
然后就是网址表格,大概长这样,总共大概一千七百多条数据。其中有少量网址是错误的,访问会得到404错误,所以在编写代码的时候还要注意错误处理。
任务分析
任务的核心自然就是分析和获取网页内容了。首先现在浏览器里面打开一个网址,看看网页上的内容是什么。
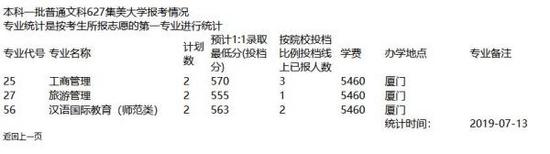
可以看到这个网页格式很乱,学校名字什么的都是混在一起的,一点也不规整,这给我们提取数据造成了不少的麻烦。不过仔细分析之后,其实问题也并不难。
首先要提取的是学校名字,可以看到学校名字和其他文字混在一起,例如"本科一批普通文科627集美大学报考情况"。本来我准备用正则表达式提取,然后发现用正则表达式好像很难。之后我多访问了几个网页,发现学校代码基本上都是数字,如果有字母的话也出现到第一位,所以我采用了以下的算法,首先将字符串从数字处分隔,右边的一个部分就包含了学校名字和“报考情况”几个字,然后删除“报考情况”即可得到学校名字。这个算法唯一的缺点就是,假如出现了字母在中间的代号,就没办法获取到学校名字了,不过实际运行之后,我幸运的发现并没有出现这种情况。
之后要提取的就是专业信息了,在网页源代码中这部分使用tr和td标签来呈现的。一开始我用的是tr加上选择器来提取,但是这个网页生成的时候很有问题,每个tr标签的样式居然还根据内容的多少而不同,导致我写死的选择器没法完美获取所有行。不过后来我发现整个网页内容都是一个表格, 除去表头和结尾的几个固定行之外,剩下的恰好就是要提取的数据行,所以直接获取tr标签,然后切片除去收尾即可。
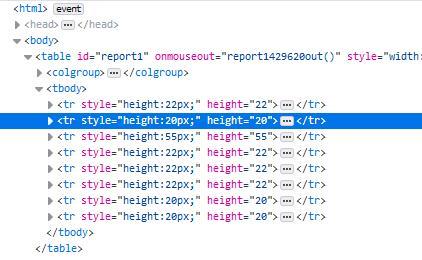
网页基本上分析完了,下面就是编写代码了。
编写代码
总共50行左右代码,我添加了注释,相信大家应该很容易就可以看懂。
第一部分代码是从网址表格读取所有url,一开始编写的时候,表格里的url是从另一个公式生成的,所以需要在加载的时候添加data_only=True才能读取到公式的结果,否则只能读取到公式本身。
第二部分是创建输出文件,然后编写表头。顺带为了调试方便,我让它如果检测到已经存在目标文件的话就删掉,在建立一个新的。
第三部分就是代码的核心了。Python代码看着可能有点奇怪,不过对照上面的分析,我想大家应该很容易看懂。需要注意保存文件在最后,假如半路代码出现异常,整个就白干了,而一千七百多条网址不可能保证都正常运行。由于输出格式是“学校名+专业信息”这样的格式,所以我获取学校名之后,还要将学校插入到每行专业信息之前。所以我这里索性直接用try-except包起来,如果出错的话只打印一下出错的网址。
import os
from requests_html import HTMLSession
from openpyxl import Workbook, load_workbook
# 从网址表格获取urls
def get_urls():
input_file = 'source.xlsx'
wb = load_workbook(input_file, data_only=True)
ws = wb.active
urls = [row[0] for row in ws.values]
wb.close()
return urls
# 输出Excel文件,如果已存在则删除已有的
out_file = 'data.xlsx'
if os.path.exists(out_file):
os.remove(out_file)
wb = Workbook()
ws = wb.active
# 编写第一行表头
ws['a1'] = '学校'
ws['b1'] = '专业代号'
ws['c1'] = '专业名称'
ws['d1'] = '计划数'
ws['e1'] = '预计1:1录取最低分(投档分)'
ws['f1'] = '按院校投档比例投档线上已报人数'
ws['g1'] = '学费'
ws['h1'] = '办学地点'
ws['i1'] = '专业备注'
# 发起网络请求,解析网页信息,并写入文件
session = HTMLSession()
urls = get_urls()
for url in urls:
import re
page = session.get(url)
page.html.encoding = 'gb2312'
try:
college_info = page.html.xpath('//td[@class="report1_1_1"]/text()', first=True)
college = re.split('\d+', college_info)[1].replace('报考情况', '')
rows = page.html.xpath('//tr')[3:-2]
for r in rows:
info = [x.text for x in r.xpath('//td')]
info.insert(0, college)
ws.append(info)
print(info)
except:
print(url)
# 保存文件
wb.save(out_file)
运行结果
好了,费了大半天的劲,代码终于完成了。让我们运行一下看看结果。整个代码大概需要运行7-8分钟,最后完成之后得到了一个500多k的Excel文件。
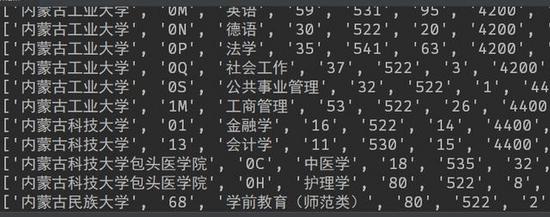
打开之后,可以发现Excel文件填的满满的,最后总共获取到了大约一万多条数据,任务圆满完成。

总结
以上所述是小编给大家介绍的50行Python代码获取高考志愿信息的实现方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!