Python爬虫爬取煎蛋网图片代码实例
这篇文章主要介绍了Python爬虫爬取煎蛋网图片代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
今天,试着爬取了煎蛋网的图片。
用到的包:
urllib.request
os
分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地。过程简单清晰明了
直接上源代码:
import urllib.request
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read()
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page')+23
b = html.find(']',a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg',a ,a+255)
if b != -1:
img_addrs.append('https:'+html[a+9:b+4]) # 'img src='为9个偏移 '.jpg'为4个偏移
else:
b = a+9
a = html.find('img src=', b)
return img_addrs
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename, 'wb') as f:
img = url_open(each)
f.write(img)
print(img_addrs)
def download_mm(folder = 'xxoo', pages = 5):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + 'page-'+ str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
download_mm()其中在主函数download_mm()中,将pages设置在了5面。
本来设置的是10,但是在程序执行的过程中。出现了404ERROR错误
即imgae_url出现了错误。尝试着在save_img()函数中加入了测试代码:print(img_addrs),

想到会不会是因为后面页数的图片,img_url的格式出现了改变,导致404,所以将pages改成5,
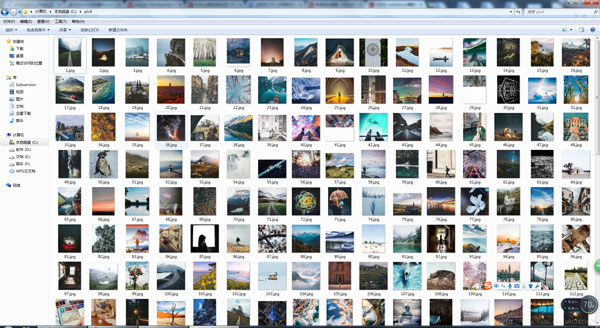
再次运行,结果没有问题,图片能正常下载:

仔细观察发现,刚好是在第五面的图片往后,出现了不可下载的问题(404)。所以在煎蛋网上,我们直接跳到第6面查看图片的url。

上图是后5面的图片url,下图是前5面的图片url

而源代码中,寻找的图片url为使用find()函数,进行定为<img src=‘'> <.jpg>中的图片url,所以后5面出现的a href无法匹配,即出现了404 ERROR。如果想要下载后续的图片,需要重新添加一个url定位
即在find中将 img src改成 a href,偏移量也需要更改。
总结:
使用find()来定位网页标签确实太过low,所以以后在爬虫中要尽量使用正则表达式和Beautifulsoup包来提高效率,而这两项我还不是特别熟,所以需要更多的训练。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。