基于python读取.mat文件并取出信息
这篇文章主要介绍了基于python读取.mat文件并取出信息,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
导入所需包
from scipy.io import loadmat
读取.mat文件
随便从下面文件里读取一个:
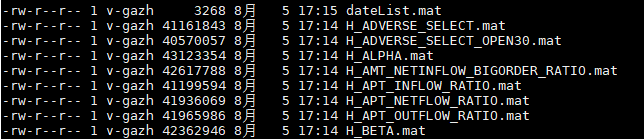
m = loadmat('H_BETA.mat') # 读出来的 m 是一个dict(字典)数据结构
读出来的m内容:
m:{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Mon Aug 5 17:14:09 2019',
'__version__': '1.0',
'__globals__': [],
'H_BETA': array([[ 0.68508148, 0.36764355, 0.73505849, ..., 0.27600164,
0.67968929, 0.70506438],
[ 0.74920812, 1.10949748, 0.47506305, ..., 0.32871445,
0.61247345, 1.06948844],
[ 0.83311522, 1.06321302, 0.97364609, ..., 0.85837753,
0.96296771, 1.46095171],
...,
[ nan, nan, nan, ..., nan,
nan, -9.04648469],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
In [29]: m.keys() Out[29]: dict_keys(['__header__', '__version__', '__globals__', 'H_BETA'])
取出.mat里所需信息
.mat 文件里的数据结构是 dict ,所以取值要按照 key:value 的形式:
In [30]: m['H_BETA']
Out[30]:
array([[ 0.68508148, 0.36764355, 0.73505849, ..., 0.27600164,
0.67968929, 0.70506438],
[ 0.74920812, 1.10949748, 0.47506305, ..., 0.32871445,
0.61247345, 1.06948844],
[ 0.83311522, 1.06321302, 0.97364609, ..., 0.85837753,
0.96296771, 1.46095171],
...,
[ nan, nan, nan, ..., nan,
nan, -9.04648469],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan]])
In [31]: type(m['H_BETA'])
Out[31]: numpy.ndarray
预处理数据
上面读出来的数据是 ndarray 类型,为了方便数据的展示,我们可以将其转换为,pandas的DataFrame:
In [32]: import pandas as pd
In [33]: df = pd.DataFrame(m['H_BETA'])
In [34]: df.head()
Out[34]:
1 2 3 4 5 6 7 8 9 10
0.685081 0.367644 0.735058 0.085046 0.104332 0.560731 0.350219 0.758185 0.303823 0.114022 0.452877
0.749208 1.109497 0.475063 0.896100 1.117772 0.611356 0.662669 0.603077 0.863930 0.756870 0.725808
0.833115 1.063213 0.973646 0.935061 0.631670 0.916800 0.662993 0.543231 0.671558 1.027954 0.526402
0.488906 0.932741 0.956622 0.573116 0.893764 0.987304 0.380807 1.211157 0.550213 0.898408 1.153289
0.440694 0.503209 0.509693 0.477054 0.344717 -0.054662 1.124213 0.344906 0.612898 0.217625 -0.129715
[5 rows x 2111 columns]
如此,数据就比较规整了,是保存成文件,还是做其他处理,就by yourself啦!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。