yipeiwu_com6年前
本人想搞个采集微信文章的网站,无奈实在从微信本生无法找到入口链接,网上翻看了大量的资料,发现大家的做法总体来说大同小异,都是以搜狗为入口。下文是笔者整理的一份python爬取微信文章的代...
yipeiwu_com6年前
网络 通用 urllib -网络库(stdlib)。 requests -网络库。 grab...
yipeiwu_com6年前
直接上需求和代码 首先是需要爬取的链接和网页:http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&pa...
yipeiwu_com6年前
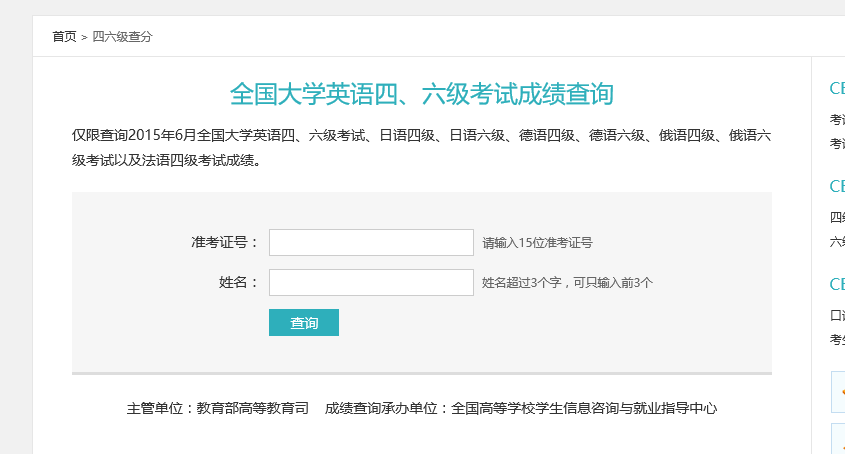
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态...
yipeiwu_com6年前
最近学习了python和爬虫,想写一个程序练练手,所以我就想到了大家都比较关心的自己的博客访问量,使用python来获取自己博客的访问量,这也是后边我将要进行的项目的一部分,后边我会对博...
yipeiwu_com6年前
一直想做个能帮我过滤出优质文章和博客的平台 给它取了个名 叫Moven。。 把实现它的过程分成了三个阶段: 1. Downloader: 对于指定的url的下载 并把获得的内容传递给An...
yipeiwu_com6年前
自上一篇文章 Z Story : Using Django with GAE Python 后台抓取多个网站的页面全文 后,大体的进度如下: 1.增加了Cron: 用来告诉程序每隔30分...
yipeiwu_com6年前
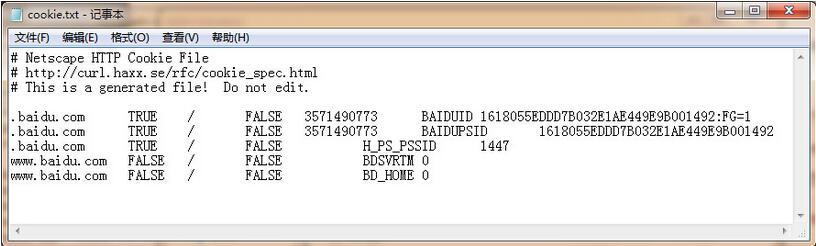
之前一篇文章我们学习了爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用。 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份、进行session跟踪而...
yipeiwu_com6年前
本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理。 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网...
yipeiwu_com6年前
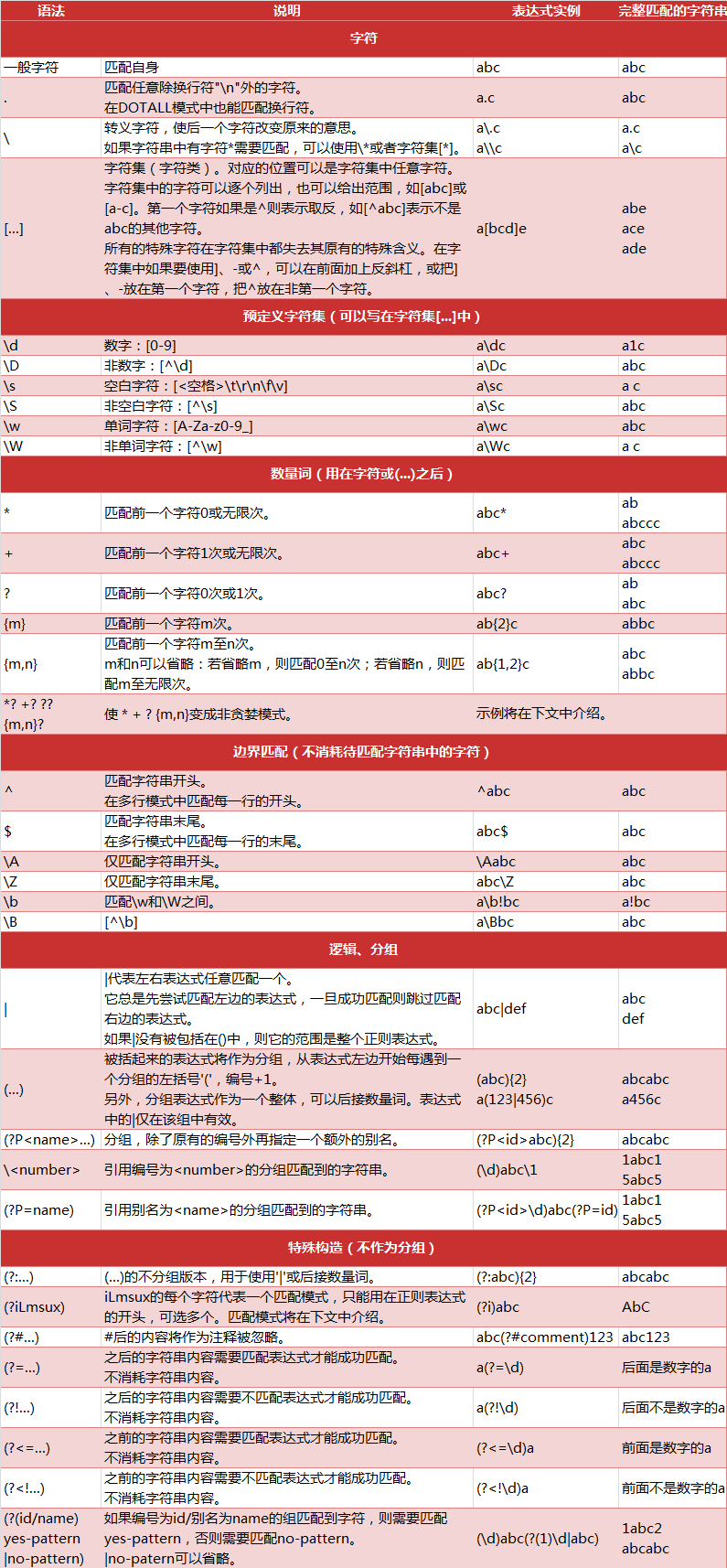
面对大量杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特...