yipeiwu_com6年前
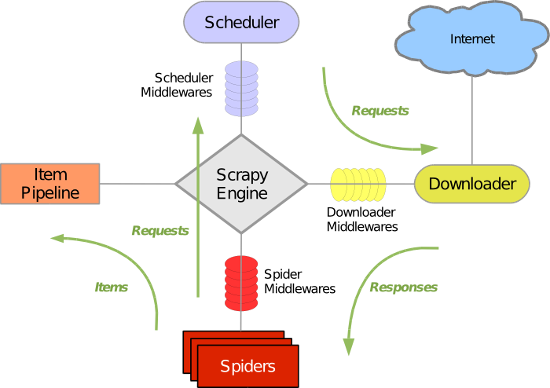
安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7)。官方文档中介绍了三种...
yipeiwu_com6年前
网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人。当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个“机器人”其实也就是一段程序,并且它...
yipeiwu_com6年前
超文本传输协议http构成了万维网的基础,它利用URI(统一资源标识符)来识别Internet上的数据,而指定文档地址的URI被称为URL(既统一资源定位符),常见的URL指向文件、目录...
yipeiwu_com6年前
基本模块 python爬虫,web spider。爬取网站获取网页数据,并进行分析提取。 基本模块使用的是 urllib,urllib2,re,等模块 基本用法,例子: (1...
yipeiwu_com6年前
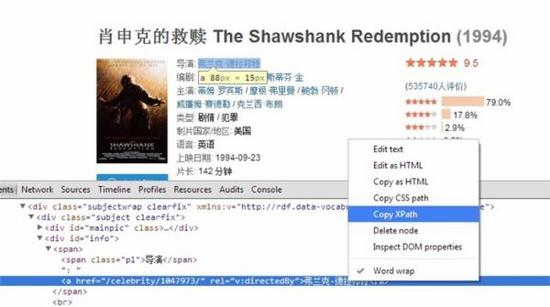
一、简单配置,获取单个网页上的内容。 (1)创建scrapy项目 scrapy startproject getblog (2)编辑 items.py # -*-...
yipeiwu_com6年前
提起python做网络爬虫就不得不说到强大的组件urllib2。在python中正是使用urllib2这个组件来抓取网页的。urllib2是Python的一个获取URLs(Uniform...
yipeiwu_com6年前
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题。 1、抓取APP数据包 方法详细可以参考这篇博文:Fiddle...
yipeiwu_com6年前
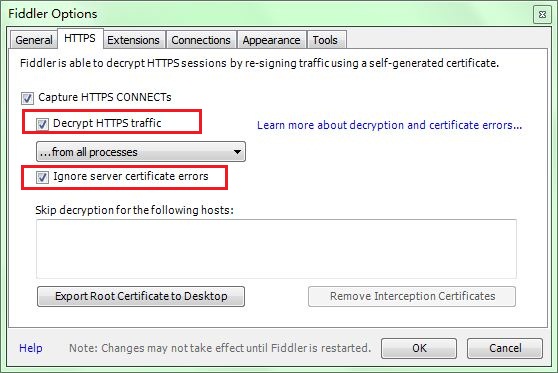
Fiddler,这个是所有软件开发者必备神器!这款工具不仅可以抓取PC上开发web时候的数据包,而且可以抓取移动端(Android,Iphone,WindowPhone等都可以)。 第一...
yipeiwu_com6年前
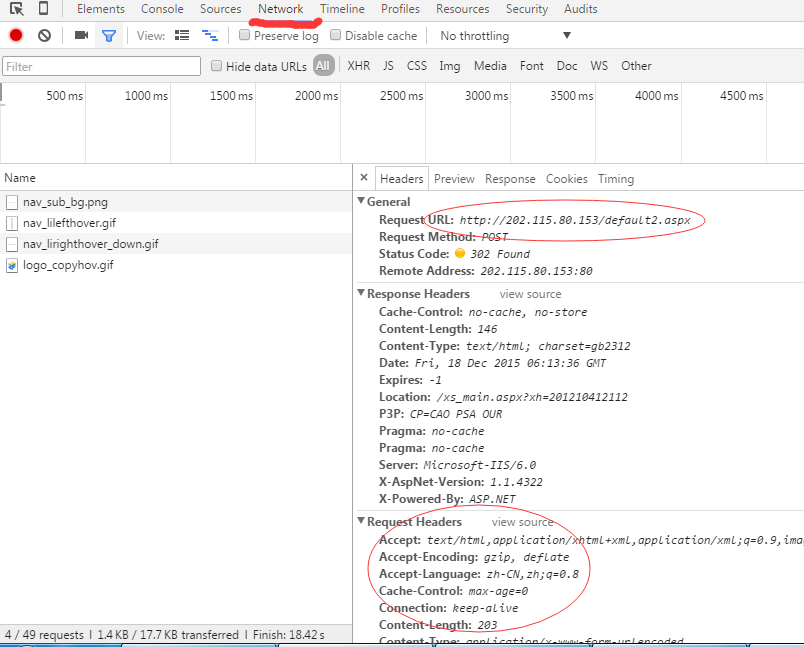
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法。python提供了强大的url库,想做到这个并不难。这里以登录学校教务系统为例,做一个简单的例子。 首先得明白coo...
yipeiwu_com6年前
网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 1. 网络爬虫的定义 网络蜘蛛是通过网页的链接地址来寻找网页的...