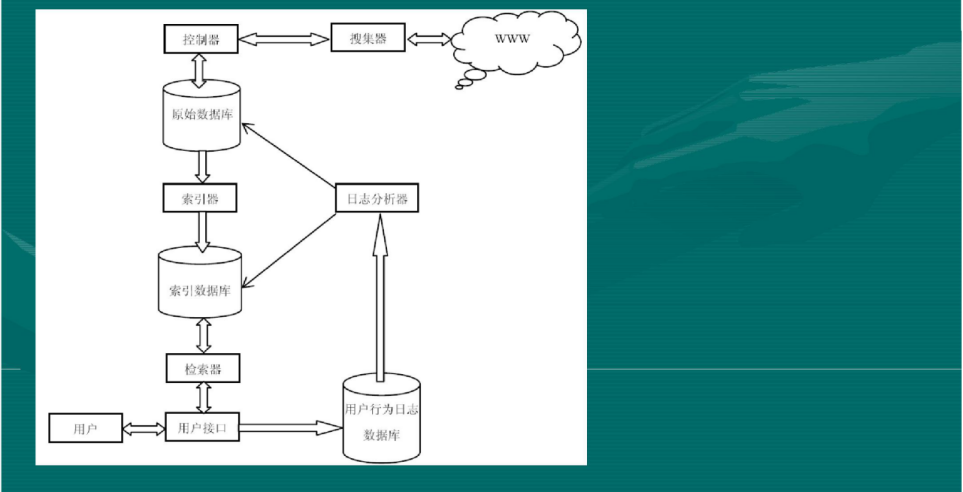
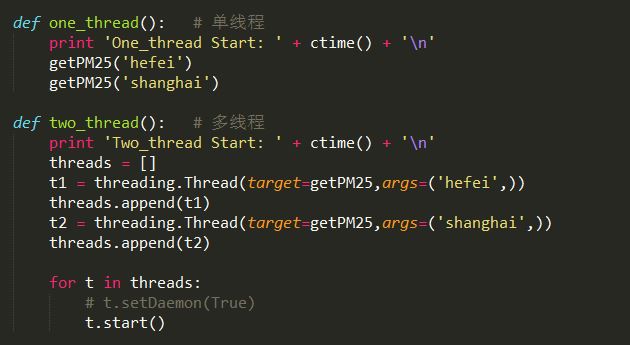
python网络爬虫采集联想词示例
python爬虫_采集联想词代码
#coding:utf-8
import urllib2
import urllib
import re
import time
from random import choice
#特别提示,下面这个list中的代理ip可能失效,请换上有效的代理ip
iplist = ['27.24.158.153:81','46.209.70.74:8080','60.29.255.88:8888']
list1 = ["集团","科技"]
for item in list1:
ip= choice(iplist)
gjc = urllib.quote(item)
url = "http://sug.so.360.cn/suggest/word?callback=suggest_so&encodein=utf-8&encodeout=utf-8&word="+gjc
headers = {
"GET":url,
"Host":"sug.so.360.cn",
"Referer":"http://www.so.com/",
"User-Agent":"sMozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17",
}
proxy_support = urllib2.ProxyHandler({'http':'http://'+ip})
opener = urllib2.build_opener(proxy_support)
urllib2.install_opener( opener )
req = urllib2.Request(url)
for key in headers:
req.add_header(key,headers[key])
html = urllib2.urlopen(req).read()
ss = re.findall("\"(.*?)\"",html)
for item in ss:
print item
time.sleep(2)