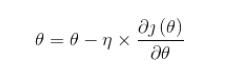Python实现的百度站长自动URL提交小工具
URL提交是百度提供的一个站长工具,用于给站长提供手工收录某些URL的接口,但是该接口有验证码识别部分,比较难弄。所以编写了如下程序进行验证码自动识别:
主要思路
获取多个验证码,提交到 http://lab.ocrking.com/ 进行多次识别,然后计算每个验证码图片识别出来的 字母或数字 进行统计,得出统计率最高的 即为验证码。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import time
import json
import re
if __name__ == "__main__":
i = 1
s = requests.session()
s.headers.update({'Referer':'http://zhanzhang.baidu.com/sitesubmit/index','User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.154 Safari/537.36'})
r = s.get('http://zhanzhang.baidu.com/sitesubmit/index')
s2 = requests.session()
r = s.post('http://zhanzhang.baidu.com/captcha',data={'async':'false','n':time.time()})
url = json.loads(r.content)['url']
temp = []
while 1:
try:
r = s.get(url)
img_data = r.content
r = s2.get('http://lab.ocrking.com/')
try:
content = ' '.join(r.content.split())
sid = re.findall(r'"sid" : "(.+?)"',content)[0]
hash_1 = re.findall(r'"hash" : "(.+?)"',content)[0]
timestamp = re.findall(r'"timestamp" : "(.+?)"',content)[0]
except:
print 'error on get orking info!'
continue
files = {'Filedata':('icode.jpeg', img_data)}
data = {'Filename':'icode.jpeg','sid':sid,'hash':hash_1,'timestamp':timestamp}
r = s2.post('http://lab.ocrking.com/upload.html',files = files,data= data)
r = s2.post('http://lab.ocrking.com/ocrking.html',data={'upfile':r.content,'type':'captcha','charset':'7'})
icode = re.findall(r'<OcrResult>(.+?)</OcrResult>',r.content)[0]
if len(icode) != 4 :
continue
temp.append(icode)
i = i + 1
if i == 3 :
break
except Exception,e:
print e
pass
a = {'0':{},'1':{},'2':{},'3':{}}
for aa in temp:
i = 0
while i <=3 :
try:
a[str(i)][aa[i]] = a[str(i)][aa[i]] + 1
except:
a[str(i)][aa[i]] = 1
i = i + 1
icode = ['','','','']
for index in a:
temp_times = 0
for index_1 in a[index]:
if a[index][index_1] >= temp_times :
temp_times = a[index][index_1]
icode[int(index)] = index_1
icode = ''.join(icode)
img_name = 'temp\\'+icode+'.png'
file_object = open(img_name, 'w')
file_object.write(img_data)
file_object.close()
#r = s.post('http://zhanzhang.baidu.com/sitesubmit/sitepost',data={'url':'http://lab.ocrking.com/','captcha':icode})
#print r.content