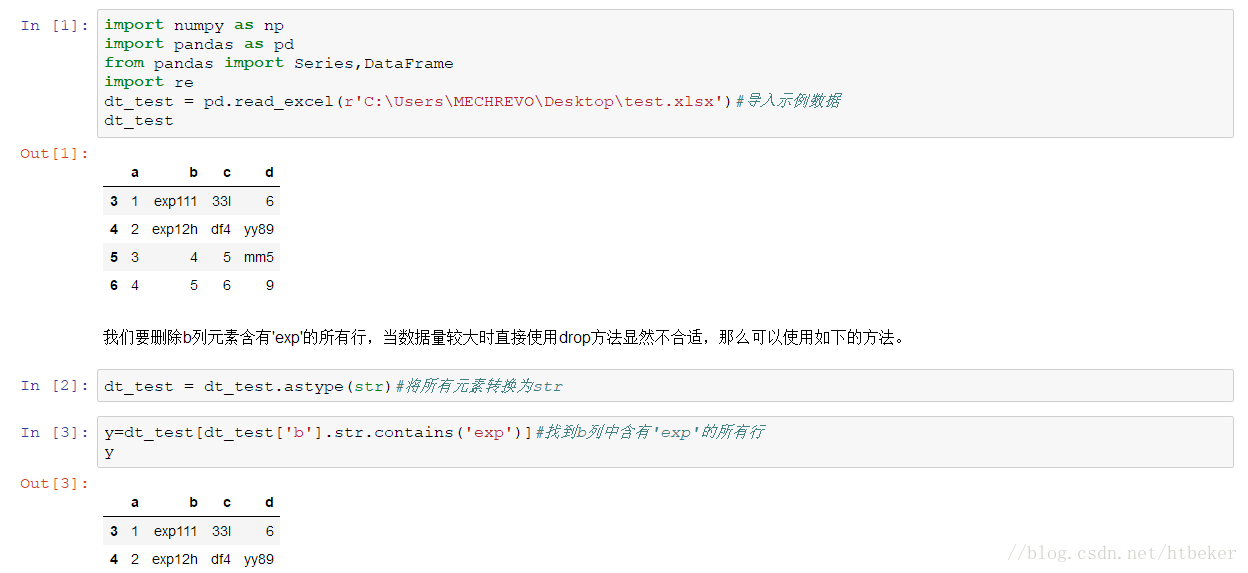
Python找出文件中使用率最高的汉字实例详解
本文实例讲述了Python找出文件中使用率最高的汉字的方法。分享给大家供大家参考。具体分析如下:
这是我初学Python时写的,为了简便,我并没在排序完后再去掉非中文字符,稍微会影响性能(大约增加了25%的时间)。
# -*- coding: gbk -*-
import codecs
from time import time
from operator import itemgetter
def top_words(filename, size=10, encoding='gbk'):
count = {}
for line in codecs.open(filename, 'r', encoding):
for word in line:
if u'\u4E00' <= word <= u'\u9FA5' or u'\uF900' <= word <= u'\uFA2D':
count[word] = 1 + count.get(word, 0)
top_words = sorted(count.iteritems(), key=itemgetter(1), reverse=True)[:size]
print '\n'.join([u'%s : %s次' % (word, times) for word, times in top_words])
begin = time()
top_words('空之境界.txt')
print '一共耗时 : %s秒' % (time()-begin)
如果想用上新方法,以及让join的可读性更高的话,这样也是可以的:
# -*- coding: gbk -*-
import codecs
from time import time
from operator import itemgetter
from heapq import nlargest
def top_words(filename, size=10, encoding='gbk'):
count = {}
for line in codecs.open(filename, 'r', encoding):
for word in line:
if u'\u4E00' <= word <= u'\u9FA5' or u'\uF900' <= word <= u'\uFA2D':
count[word] = 1 + count.get(word, 0)
top_words = nlargest(size, count.iteritems(), key=itemgetter(1))
for word, times in top_words:
print u'%s : %s次' % (word, times)
begin = time()
top_words('空之境界.txt')
print '一共耗时 : %s秒' % (time()-begin)
或者让行数更少(好囧的列表综合):
# -*- coding: gbk -*-
import codecs
from time import time
from operator import itemgetter
def top_words(filename, size=10, encoding='gbk'):
count = {}
for word in [word for word in codecs.open(filename, 'r', encoding).read() if u'\u4E00' <= word <= u'\u9FA5' or u'\uF900' <= word <= u'\uFA2D']:
count[word] = 1 + count.get(word, 0)
top_words = sorted(count.iteritems(), key=itemgetter(1), reverse=True)[:size]
print '\n'.join([u'%s : %s次' % (word, times) for word, times in top_words])
begin = time()
top_words('空之境界.txt')
print '一共耗时 : %s秒' % (time()-begin)
此外还可以引入with语句,这样只需一行就能获得异常安全性。
3者性能几乎一样,结果如下:
的 : 17533次 是 : 8581次 不 : 6375次 我 : 6168次 了 : 5586次 一 : 5197次 这 : 4394次 在 : 4264次 有 : 4188次 人 : 4025次 一共耗时 : 0.5秒
引入psyco模块的成绩:
的 : 17533次 是 : 8581次 不 : 6375次 我 : 6168次 了 : 5586次 一 : 5197次 这 : 4394次 在 : 4264次 有 : 4188次 人 : 4025次 一共耗时 : 0.280999898911秒
注:测试文件为778KB的GBK编码,40余万字。
希望本文所述对大家的Python程序设计有所帮助。