Python脚本实现虾米网签到功能
本文实例讲述了Python脚本实现虾米网签到功能的方法。分享给大家供大家参考,具体如下:
概述
这个脚本完成了自动登录虾米网、签到的功能。
大致要用到urllib、urllib2、cookielib这几个模块。其实就是用python实现向指定的url去post数据。
至于我怎么知道在浏览器里面登录和签到时浏览器都向服务器post了什么数据的问题,可以用强大的chrome:F12->Network里面可以看得到。有的服务器登录成功后会让客户端浏览器跳转或者立即刷新一次页面等等,会把登录时向服务器post的数据刷没掉,那么就要用到强大的抓包软件——WireShark来分析。比如用chrome:
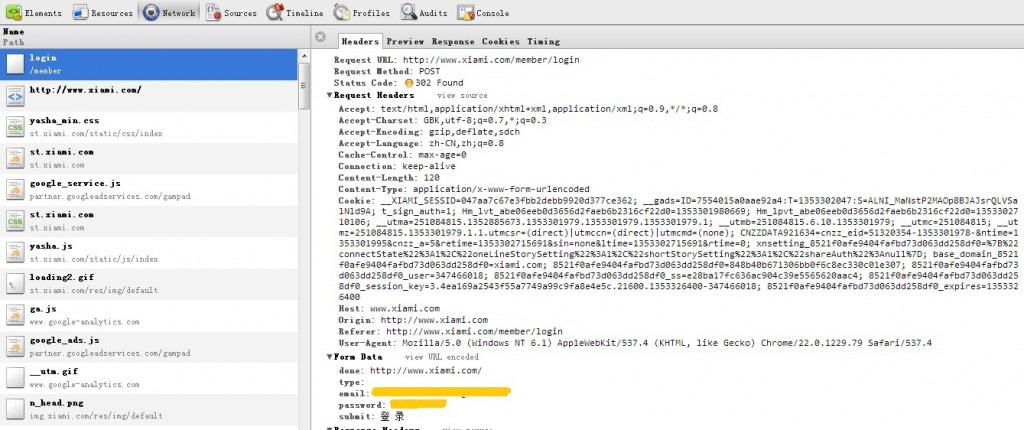
然后就可以写了,构造Request Headers和要Post的Data(就是Chrome里的Form Data),ID和Pwd是明文传输,呵呵。
代码
下面是代码:
# -*- coding: cp936 -*-
'''''
Created on 2012-11-15
@author: liushuai
'''
import urllib, urllib2, cookielib, sys
class LoginXiami:
login_header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.79 Safari/537.4'}
signin_header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.79 Safari/537.4', 'X-Requested-With':'XMLHttpRequest', 'Content-Length':0, 'Origin':'http://www.xiami.com', 'Referer':'http://www.xiami.com/'}
email = ''
password = ''
cookie = None
cookieFile = './cookie.dat'
def __init__(self, email, pwd):
self.email = email
self.password = pwd
self.cookie = cookielib.LWPCookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookie))
urllib2.install_opener(opener)
def login(self):
postdata = {'email':self.email, 'password':self.password, 'done':'http://www.xiami.com', 'submit':'%E7%99%BB+%E5%BD%95'}
postdata = urllib.urlencode(postdata)
print 'Logining...'
req = urllib2.Request(url='http://www.xiami.com/member/login', data=postdata, headers=self.login_header)
result = urllib2.urlopen(req).read()
self.cookie.save(self.cookieFile)
result = str(result).decode('utf-8').encode('gbk')
if 'Email 或者密码错误' in result:
print 'Login failed due to Email or Password error...'
sys.exit()
else :
print 'Login successfully!'
def signIn(self):
postdata = {}
postdata = urllib.urlencode(postdata)
print 'signing...'
req = urllib2.Request(url='http://www.xiami.com/task/signin', data=postdata, headers=self.signin_header)
result = urllib2.urlopen(req).read()
result = str(result).decode('utf-8').encode('gbk')
self.cookie.save(self.cookieFile)
try:
result = int(result)
except ValueError:
print 'signing failed...'
sys.exit()
except:
print 'signing failed due to unknown reasons ...'
sys.exit()
print 'signing successfully!'
print self.email,'have signed', result, 'days continuously...'
if __name__ == '__main__':
user = LoginXiami('你的登录邮箱', '你的密码')
user.login()
user.signIn()
然后运行一下脚本就可以登录、签到了。

后记
有的Discuz!论坛据说是为了防止用户用网页之外的途径向服务器post数据,服务器在每个用户每次登录成功后生成一个叫formhash的值,作为表单的隐藏域返回给客户端(服务端也有保存)。

客户端在向服务器post数据的时候,这个值会作为表单的一项数据“神不知鬼不觉”(因为是表单的隐藏域)地一同post过去,服务端收到客户端的post请求后,和服务端的formhash值作对比,就能知道是否是通过浏览器页面的方式post的数据了。
不过如果真的是为了防止这,这个做法真的有用吗?我试了一下,只需用简单的正则分析下登录成功返回的html,找到formhash值,再用上述方法和理论post过去即可,成功的完成了签到的功能。
反正不管怎么说,就是用脚本“假装”地完成了一下用浏览器登录并签到的过程。
附:由于网站可能进行改版或升级,那么向服务器中post的数据可能会有变化,那么就要对代码进行相应调整,故代码仅供研究和学习参考之用。
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。