将字典转换为DataFrame并进行频次统计的方法
首先将一个字典转化为DataFrame,然后以DataFrame中的列进行频次统计。
代码如下:
import pandas as pd
a={'one':['A','A','B','C','C','A','B','B','A','A'],
'tao':['B','B','C','C','A','A','C','B','C','A'],
'three':['C','B','A','A','B','B','B','A','C','D']}
b=pd.DataFrame(a)
b.describe()
b是转换后DataFrame,显示如表格:
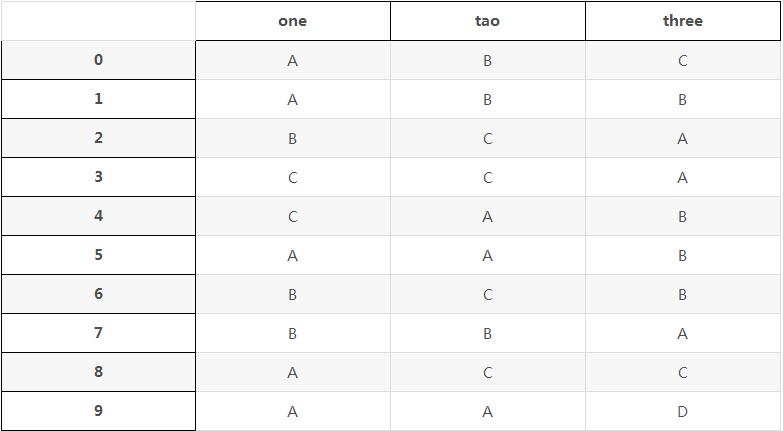
one tao three 0 A B C 1 A B B 2 B C A 3 C C A 4 C A B 5 A A B 6 B C B 7 B B A 8 A C C 9 A A D
频次统计如表格:
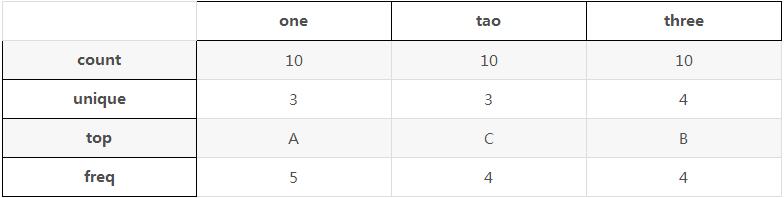
one tao three count 10 10 10 unique 3 3 4 top A C B freq 5 4 4
其中count是总共变量数量,unique是每列有几个变量,top是频次最高的那个变量,freq是频次最高变量出现的频次。
以上这篇将字典转换为DataFrame并进行频次统计的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。
