利用python将pdf输出为txt的实例讲解
一个礼拜前一个同学问我这个事情,由于之前在参加华为的比赛,所以赛后看了一下,据说需要用到pdfminer这个包。于是安装了一下,安装过程很简单:
sudo pip install pdfminer;
中间也没有任何的报错。至于如何调用,本人也没有很好的研究过pdfminer这个库,于是开始了百度……
官方文档:http://www.unixuser.org/~euske/python/pdfminer/index.html
完全使用python编写。 (适用于2.4或更新版本)
解析,分析,并转换成PDF文档。
PDF-1.7规范的支持。 (几乎)
中日韩语言和垂直书写脚本支持。
各种字体类型(Type1、TrueType、Type3,和CID)的支持。
基本加密(RC4)的支持。
PDF与HTML转换。
纲要(TOC)的提取。
标签内容提取。
通过分组文本块重建原始的布局。
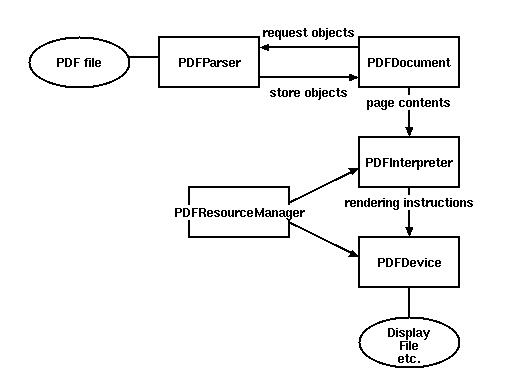
一些基本的类
PDFParser:从一个文件中获取数据
PDFDocument:保存获取的数据,和PDFParser是相互关联的
PDFPageInterpreter处理页面内容
PDFDevice将其翻译成你需要的格式
PDFResourceManager用于存储共享资源,如字体或图像。
简单的实现
读取test.pdf输出为output.txt:
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
fp = open('test.pdf', 'rb')
#来创建一个pdf文档分析器
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
document = PDFDocument(parser)
# 检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建一个PDF资源管理器对象来存储共赏资源
rsrcmgr=PDFResourceManager()
# 设定参数进行分析
laparams=LAParams()
# 创建一个PDF设备对象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 创建一个PDF解释器对象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 处理每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('output.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')
以上这篇利用python将pdf输出为txt的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。