Python解析并读取PDF文件内容的方法
本文实例讲述了Python解析并读取PDF文件内容的方法。分享给大家供大家参考,具体如下:
一、问题描述
利用python,去读取pdf文本内容。
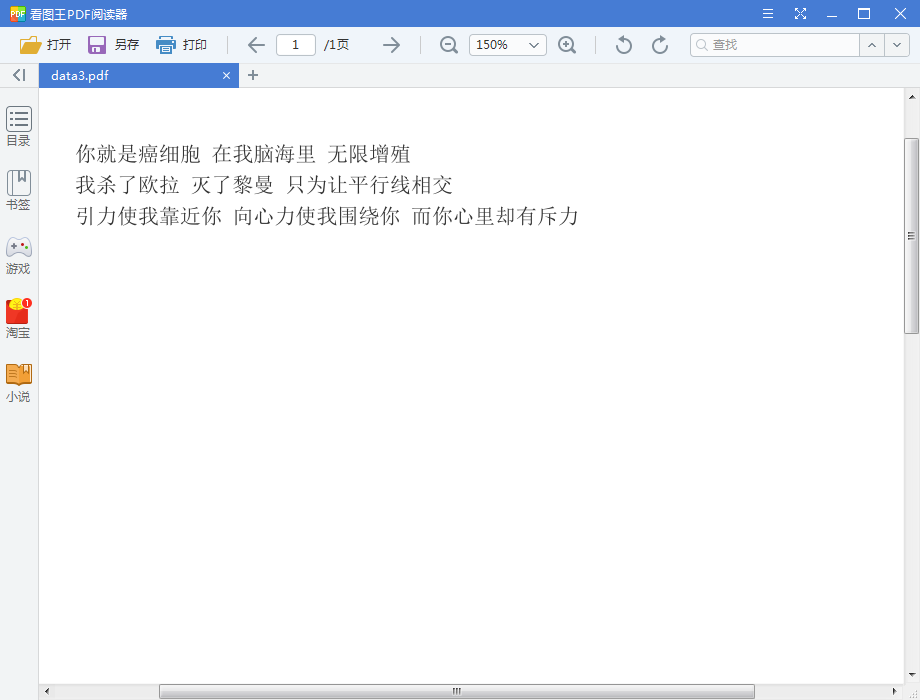
二、效果
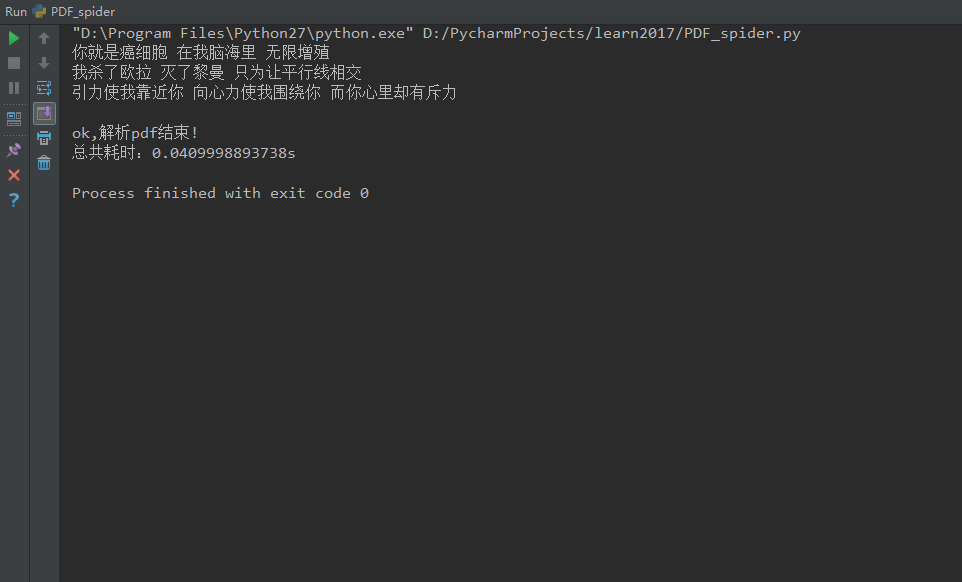
三、运行环境
python2.7
四、需要安装的库
pip install pdfminer
五、实现源代码
代码1(win64)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/data3.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'
代码2(win32)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument(praser)
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in PDFPage.create_pages(doc): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/36.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'
更多Python相关内容感兴趣的读者可查看本站专题:《Python文件与目录操作技巧汇总》、《Python编码操作技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。