TensorFlow实现简单卷积神经网络
本文使用的数据集是MNIST,主要使用两个卷积层加一个全连接层构建的卷积神经网络。
先载入MNIST数据集(手写数字识别集),并创建默认的Interactive Session(在没有指定回话对象的情况下运行变量)
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
sess = tf.InteractiveSession()
在定义一个初始化函数,因为卷积神经网络有很多权重和偏置需要创建。
def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) #给权重制造一些随机的噪声来打破完全对称, return tf.Variable(initial) #使用relu,给偏置增加一些小正值0.1,用来避免死亡节点 def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial)
卷积移动步长都是1代表会不遗漏的划过图片的每一个点,padding代表边界处理方式,same表示给边界加上padding让卷积的输出和输入保持同样的尺寸。
def conv2d(x,W):#2维卷积函数,x输入,w是卷积的参数,strides代表卷积模板移动步长
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding='SAME')
在正式设计卷积神经网络结构前,先定义输入的placeholder(类似于c++的cin,要求用户运行时输入)。因为卷积神经网络会利用到空间结构信息,因此需要将一维的输入向量转换为二维的图片结构。同时因为只有一个颜色通道,所以最后尺寸为【-1, 28,28, 1],-1代表样本数量不固定,1代表颜色通道的数量。
这里的tf.reshape是tensor变形函数。
x = tf.placeholder(tf.float32, [None, 784])# x 时特征 y_ = tf.placeholder(tf.float32, [None, 10])# y_时真实的label x_image = tf.reshape(x, [-1, 28, 28,1])
接下来定义第一个卷积层。
w_conv1 = weight_variable([5, 5, 1, 32]) #代表卷积核尺寸为5X5,1个颜色通道,32个不同的卷积核,使用conv2d函数进行卷积操作, b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1)
定义第二个卷积层,与第一个卷积层一样,只不过卷积核的数量变成了64,即这层卷积会提取64种特征
w_conv2 = weight_variable([5, 5, 32, 64])#这层提取64种特征 b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2)
经过两次步长为2x2的最大池化,此时图片尺寸变成了7x7,在使用tf.reshape函数,对第二个卷积层的输出tensor进行变形,将其从二维转为一维向量,在连接一个全连接层(隐含节点为1024),使用relu激活函数。
w_fc1 = weight_variable([7*7*64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
Dropout层:随机丢弃一部分节点的数据来减轻过拟合。这里是通过一个placeholder传入keep_prob比率来控制的。
#为了减轻过拟合,使用一个Dropout层 keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) #dropout层的输出连接一个softmax层,得到最后的概率输出 w_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2)
定义损失函数即评测准确率操作
#损失函数,并且定义优化器为Adam
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv),
reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
开始训练
#初始化所有参数
tf.global_variables_initializer().run()
for i in range (20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1],
keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
全部训练完成后,我们在最终的测试集上进行全面的测试,得到整体的分类准确率。
print("test accuracy %g" %accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
这个网络,参与训练的样本数量总共为100万,共进行20000次训练迭代,使用大小为50的mini_batch。
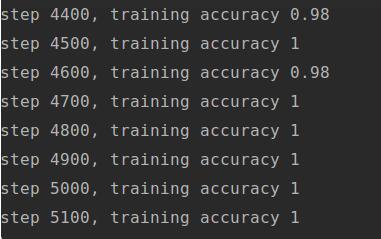
因为我安装的版本时CPU版的tensorflow,所以运行较慢,这个模型最终的准确性约为99.2%,基本可以满足对手写数字识别准确率的要求。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。