利用Anaconda简单安装scrapy框架的方法
引言:使用pip install 来安装scrapy需要安装大量的依赖库,这里我使用了Anaconda来安装scrapy,安装时只需要一条语句:conda install scrapy即可
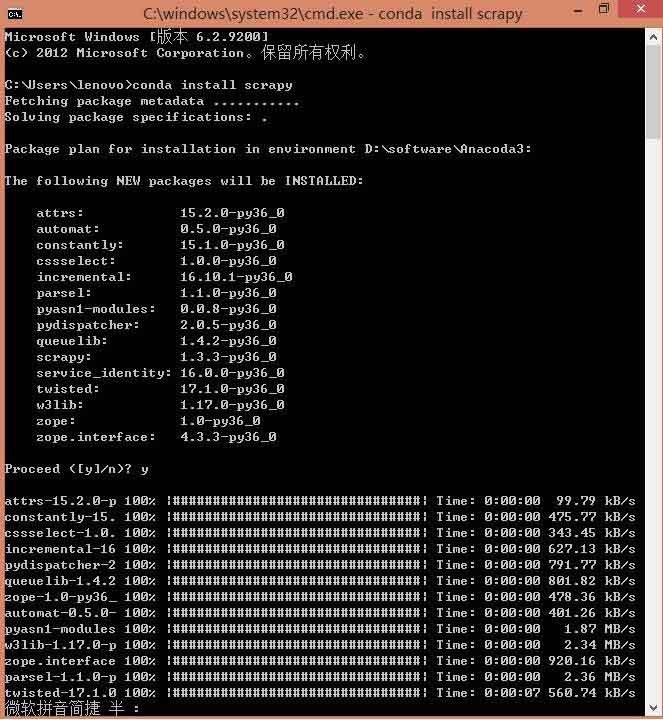
步骤1:安装Anaconda,在cmd窗口输入:conda install scrapy ,输入y回车表示允许安装依赖库
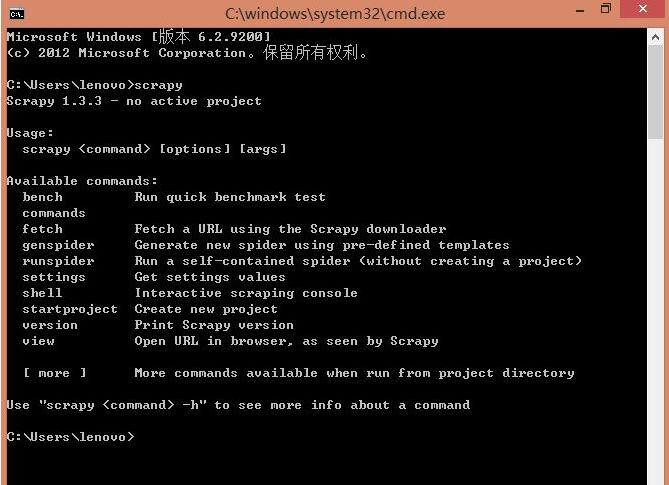
步骤2:测试scrapy是否安装成功,在dos窗口输入scrapy回车
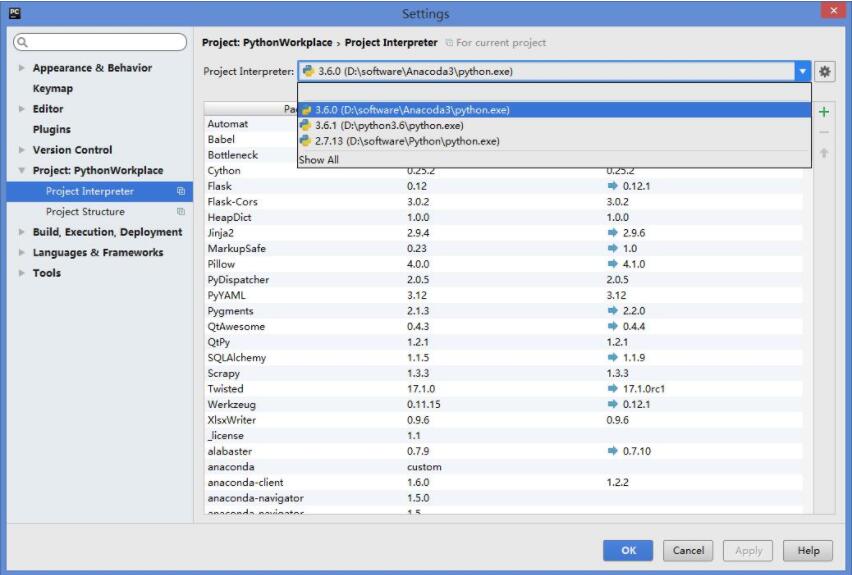
步骤3:在Pycharm-->file-->settings-->搜索project interpreter(项目解释器)-->选择Anaconda3的python.exe --〉点击“OK”,千万不要点apply,可能会让你更新一大堆东西
万一它让你更新一大堆库的话,反正我是等他更新完了........

步骤4:在pycharm中输入import scrapy ,如果不报错,应该就是可以用了

后言:之前的一些项目代码不能用了,我只好切换回Python3.6,根据自己需要切换即可,注意点击“OK”而不是Apply!!!
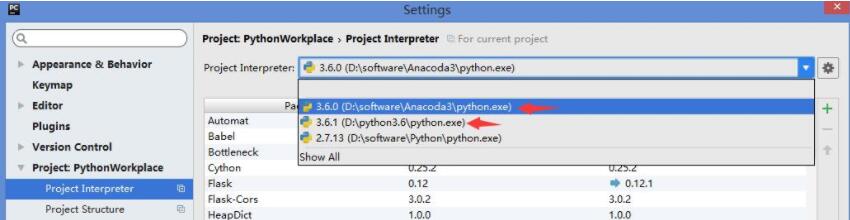
疑惑:那我这样是不是在Anaconda中需要用以前的库的话,就需要重新安装依赖库了?那真是醉了,为了学个scrapy也是蛮拼的。
以上这篇利用Anaconda简单安装scrapy框架的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。