数组保存为txt, npy, csv 文件, 数组遍历enumerate的方法
Numpy提供了几种数据保存的方法。
以3*4数组a为例:
1. a.tofile("filename.bin")
这种方法只能保存为二进制文件,且不能保存当前数据的行列信息,文件后缀不一定非要是bin,也可以为txt,但不影响保存格式,都是二进制。
这种保存方法对数据读取有要求,需要手动指定读出来的数据的的dtype,如果指定的格式与保存时的不一致,则读出来的就是错误的数据。
b = numpy.fromfile("filename.bin",dtype = **)
读出来的数据是一维数组,需要利用
b.shape = 3,4重新指定维数。
2.import numpy
numpy.save("filename.npy",a)
利用这种方法,保存文件的后缀名字一定会被置为.npy,这种格式最好只用
numpy.load("filename")来读取。
3.import numpy
numpy.savetxt("filename.txt",a)
numpy.loadtxt("filename.txt")
用于处理一维和二维数组
4.import numpy
numpy.savetxt('new.csv', my_matrix, delimiter = ',')
numpy.loadtxt(open("c:\\1.csv","rb"),delimiter=",",skiprows=0)
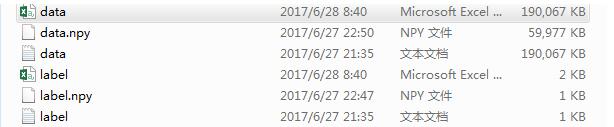
注意: txt ,csv 占得内存比npy 大的多, 推荐保存为npy文件。 下图个文件大小.
5. 遍历
y=[] for index, item in enumerate(yy): y.append(int(item)) y=array(y) print(y.dtype)
以上这篇数组保存为txt, npy, csv 文件, 数组遍历enumerate的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。


