Numpy中的mask的使用
numpy中矩阵选取子集或者以条件选取子集,用mask是一种很好的方法
简单来说就是用bool类型的indice矩阵去选择,
mask = np.ones(X.shape[0], dtype=bool) X[mask].shape mask.shape mask[indices[0]] = False mask.shape X[mask].shape X[~mask].shape (678, 2) (678,) (678,) (675, 2) (3, 2)
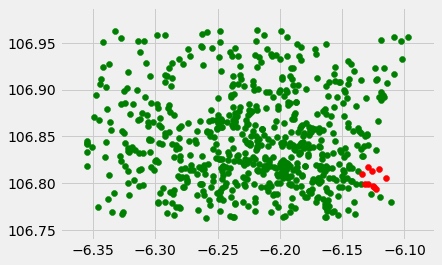
例如我们这里用来选取全部点中KNN选取的点以及所有剩余的点
from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(10).fit(X) _,indices = nbrs.kneighbors(X) mask = np.ones(X.shape[0], dtype=bool) mask[indices[0]] = False plt.scatter(X[mask][:,0],X[mask][:,1],c='g') plt.scatter(X[~mask][:,0],X[~mask][:,1],c='r')
带条件选择替换,比如我们需要将a矩阵内某条件的行置换为888剩余置换为999,可以直接用mask或者再用where一步搞定:
mask = np.ones(a.shape,dtype=bool) #np.ones_like(a,dtype=bool) mask[indices] = False a[~mask] = 999 a[mask] = 888 ############# np.where(mask, 888, 999)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。