pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
代码如下,步骤流程在代码注释中可见:
# -*- coding: utf-8 -*-
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
from pyspark import SparkContext
#初始化数据
#初始化pandas DataFrame
df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1', 'row2'], columns=['c1', 'c2', 'c3'])
#打印数据
print df
#初始化spark DataFrame
sc = SparkContext()
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("testDataFrame")\
.getOrCreate()
sentenceData = spark.createDataFrame([
(0.0, "I like Spark"),
(1.0, "Pandas is useful"),
(2.0, "They are coded by Python ")
], ["label", "sentence"])
#显示数据
sentenceData.select("label").show()
#spark.DataFrame 转换成 pandas.DataFrame
sqlContest = SQLContext(sc)
spark_df = sqlContest.createDataFrame(df)
#显示数据
spark_df.select("c1").show()
# pandas.DataFrame 转换成 spark.DataFrame
pandas_df = sentenceData.toPandas()
#打印数据
print pandas_df
程序结果:
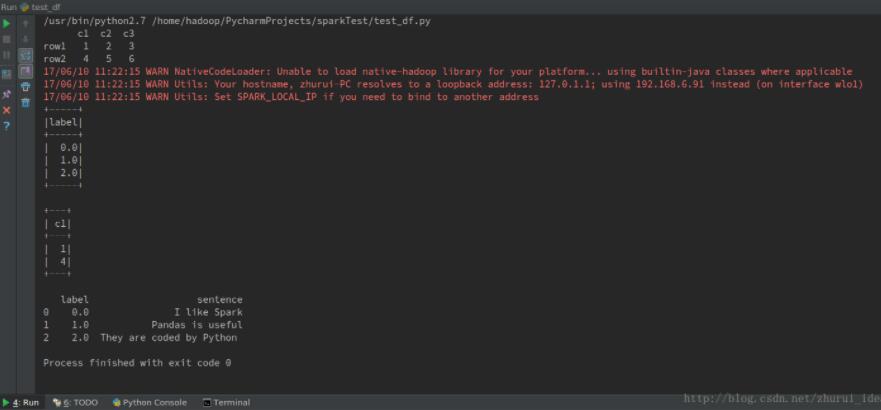
以上这篇pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。