Python数据集切分实例
在处理数据过程中经常要把数据集切分为训练集和测试集,因此记录一下切分代码。
''' data:数据集 test_ratio:测试机占比 如果data为numpy.numpy.ndarray直接使用此代码 如果data为pandas.DatFrame类型则 return data[train_indices],data[test_indices] 修改为 return data.iloc[train_indices],data.iloc[test_indices] ''' def split_train(data,test_ratio): shuffled_indices=np.random.permutation(len(data)) test_set_size=int(len(data)*test_ratio) test_indices =shuffled_indices[:test_set_size] train_indices=shuffled_indices[test_set_size:] return data[train_indices],data[test_indices]
测试代码如下:
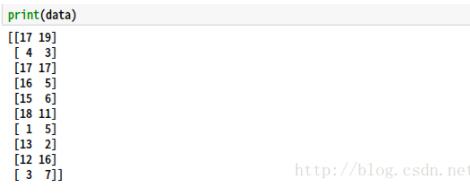
import numpy as np import pandas as pd data=np.random.randint(100,size=[25,4]) print(data)
结果如下:
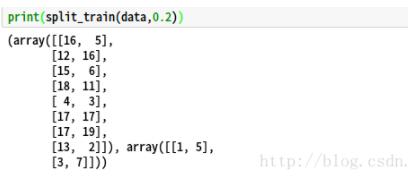
从上图可以看出,原数据集按照5:1被随机分为两部分。但是此种方法存在一个缺点–每次调用次函数切分同一个数据集切分出来的结果都不一样,因此常在np.random.permutation(len(data))先调用np.random.seed(int)函数,来确保每次切分来的结果相同。
因此将上述函数改为:
def split_train(data,test_ratio): np.random.seed(43) shuffled_indices=np.random.permutation(len(data)) test_set_size=int(len(data)*test_ratio) test_indices =shuffled_indices[:test_set_size] train_indices=shuffled_indices[test_set_size:] return data[train_indices],data[test_indices]
这个函数np.random.seed(43)当参数为同一整数时产生的随机数相同。
以上这篇Python数据集切分实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。