Python3.5 处理文本txt,删除不需要的行方法
这个问题是在问答里看到的,给了回答顺便在这里贴一下代码:
#coding:utf-8 #python3.5.1 import re file_path0 = r'G:\任务20180312\test/handle1.txt' f = open(file_path0) #读取全部内容 lines = f.readlines() #lines在这里是一个list #获取行数 nums = len(lines) #建立一个空列表 rows_get = [] #循环行数 for i in range(nums): line = lines[i] #line类型为str #开始用正则得到数字部分,并判断 #给定正则规则 p = r',(.+)' #发现每行取逗号后面部分就行 #编译正则 pattern = re.compile(p) try: #查找,用try判断是因为还存在空行 number = re.findall(pattern,line)[0] #这里number类型 str #去除空格 number = number.strip() #转换int,便于比较 number = float(number) #判断数字小于9.500和大于12.500的行删除 if number <9.500 or number>12.500: pass else: rows_get.append(i) except: continue #rows_get使我们所需要的数据 print(rows_get) #建立空字符串 text = '' for x in rows_get: #得到想要的每行数据 row = lines[x] #叠加 text = text + row with open(r'G:\任务20180312\test/handle1_get.txt','w') as f: f.write(text)
结果如下图:
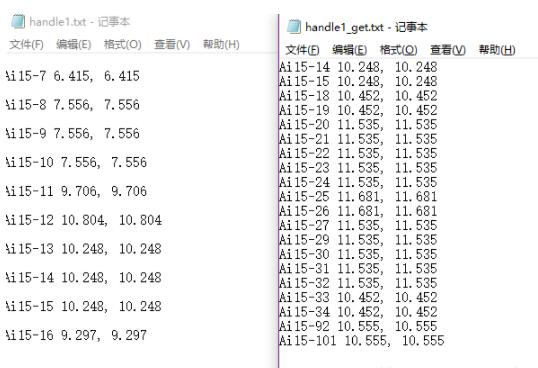
望有所帮助,望采纳!!
以上这篇Python3.5 处理文本txt,删除不需要的行方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。