windows下搭建python scrapy爬虫框架步骤
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windows下搭建scrapy框架,官方文档是建议使用集成包的,以免安装太过复杂而出现问题,首先百度scrapy,就可以找到scrapy的官方文档
1、找到windows下的框架安装的文档教程,这里建议我们安装Anaconda或者Miniconda集成包,下面我选择安装Miniconda安装包来安装scrapy框架
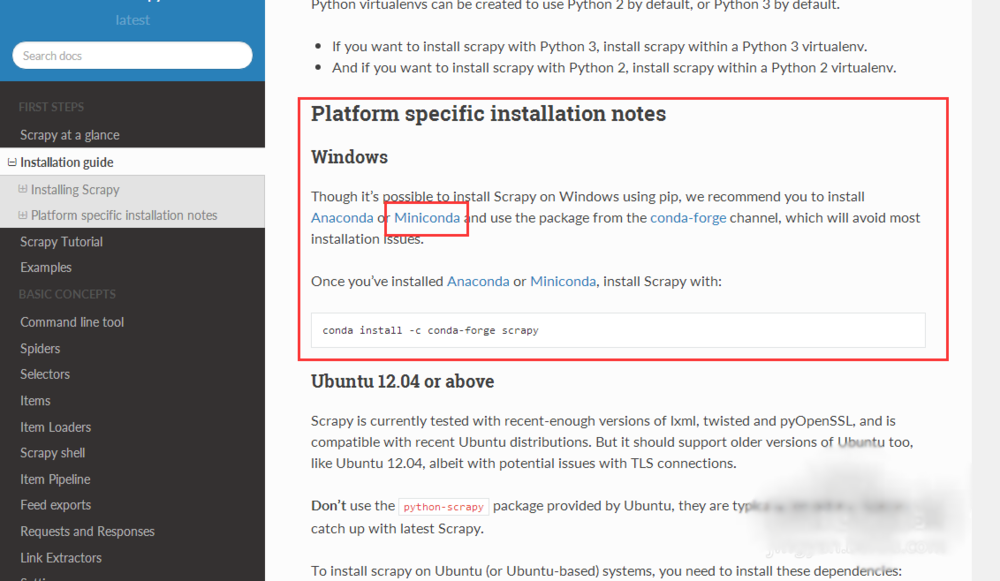
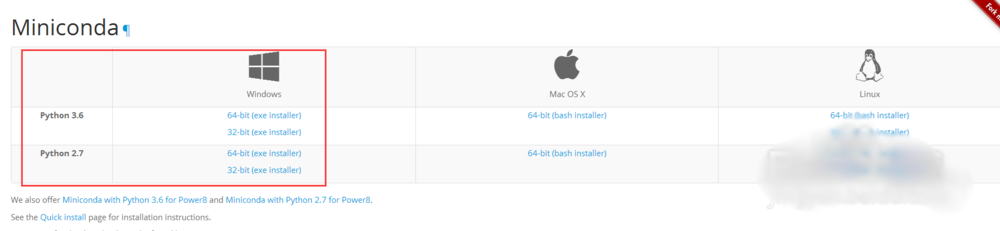
2、百度Miniconda python集成安装包,根据自己的python版本和windows版本选择对应的安装包下载即可
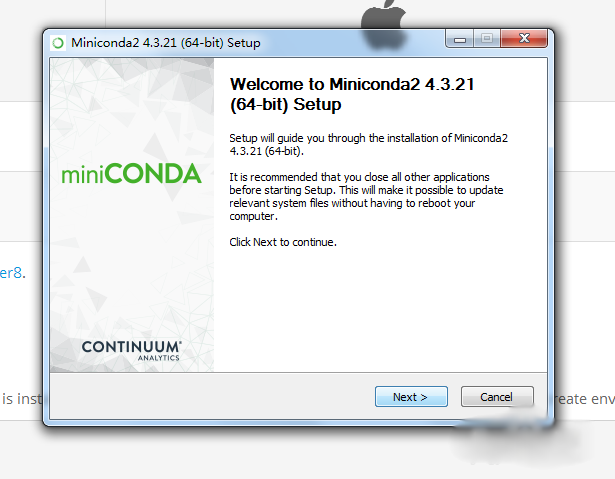
3、下载完成后进入安装界面,全程下一步即可
4、在cmd窗口中用conda list 命令检验conda是否安装成功
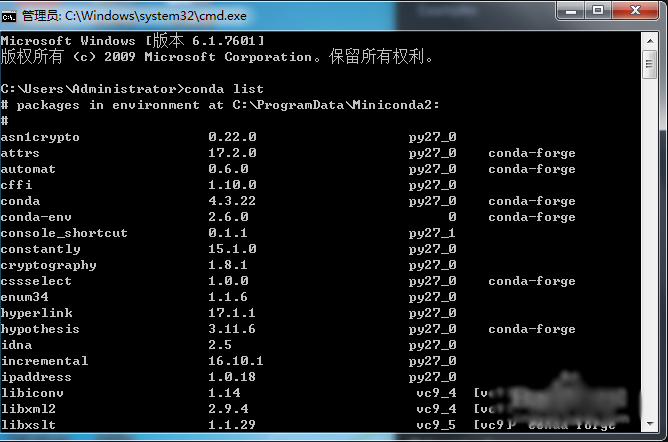
5、如果检验命令无效,检查下环境变量里是否有正确的读取路径,如果还是不行,尝试重新安装

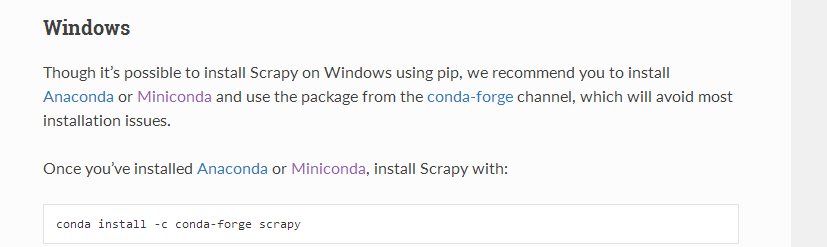
6、使用 conda install -c conda-forge scrapy 命令安装scrapy框架
7、等待框架的各个组件下载安装完成,安装界面很炫酷哦等待框架的各个组件下载安装完成,安装界面很炫酷哦
8、最后一步,使用 scrapy startproject tutorial 命令生成scrapy爬虫模版,然后就可以根据文档对scrapy爬虫模版进行改写来完成我们自己的网络爬虫了,大功告成!!!

总结:以上就是关于在WIN下安装python爬虫框架的步骤教学,感谢大家的阅读和对【听图阁-专注于Python设计】的支持。