Python设计模式之职责链模式原理与用法实例分析
本文实例讲述了Python设计模式之职责链模式原理与用法。分享给大家供大家参考,具体如下:
职责链模式(Chain Of Responsibility):使多个对象都有机会处理请求,从而避免发送者和接收者的耦合关系。将对象连成链并沿着这条链传递请求直到被处理
下面是一个设计模式的demo:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'Andy'
"""
大话设计模式
设计模式——职责链模式
职责链模式(Chain Of Responsibility):使多个对象都有机会处理请求,从而避免发送者和接收者的耦合关系。将对象连成链并沿着这条链传递请求直到被处理
(在调用时要定义好哪个实例是哪个实例的职责上一级)请求沿着定义的链条传递给可以处理请求的对象
"""
#抽象一个处理类
class Handle(object):
def __init__(self):
self.successor = ''
def setsuccessor(self, successor):
self.successor = successor
def handle_request(self,request):
pass
# 具体处理者类1
class ConcreteHandle1(Handle):
def handle_request(self,request):
if request>0 and request<=10:
print "ConcreteHandle1处理请求 ",request
else:
self.successor.handle_request(request)
# 具体处理者类2
class ConcreteHandle2(Handle):
def handle_request(self,request):
if request>10 and request<=20:
print "ConcreteHandle2处理请求 ",request
else:
self.successor.handle_request(request)
if __name__=="__main__":
c1 = ConcreteHandle1()
c2 = ConcreteHandle2()
c1.setsuccessor(c2)
for i in range(6,15,2):
c1.handle_request(i)
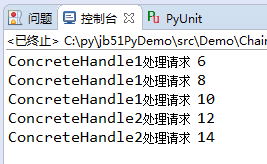
运行结果:
上面类的设计如下图:
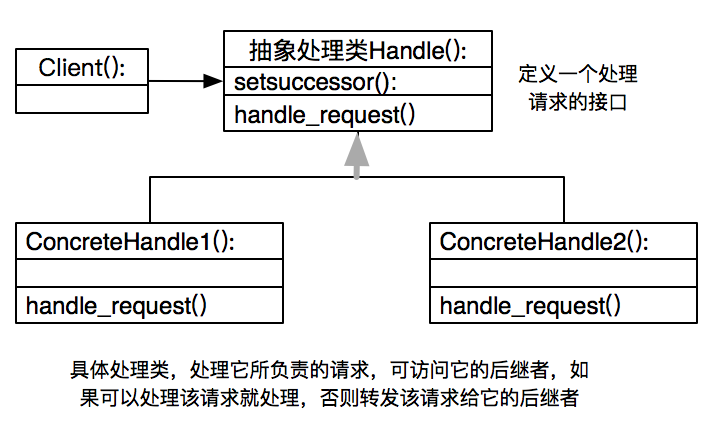
接收者和发送者都没有对方的明确信息,且链中的对象自己并不知道链的结构,职责链可简化对象的相互连接,他们仅需保持一个指向后继者的引用,而不需要保持他所有候选接收者的引用,大大降低了耦合度,可以随时增加或修改处理一个请求的结构
但是要当心,一个请求沿着职责链到达末端,都没有正确的配置而得不到处理的情况
更多关于Python相关内容可查看本站专题:《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。