python实现淘宝秒杀脚本
本文实例为大家分享了python实现淘宝秒杀脚本的具体代码,供大家参考,具体内容如下
1.安装pycharm。网上教程很多。
2.安装 Selenium 库。
Selenium支持很多浏览器,我选择的是Firefox浏览器。
因为我这里是Python3环境,自带的又pip,所以安装selenium直接使用pip安装
安装方法:
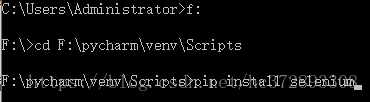
--打开cmd;
--输入命令进入Python36/Scripts(找到下图的目录)目录下;
--输入命令 pip install selenium;
--回车,等待自动安装;
--当最后一行代码出现Successfully install selenium-XX时,表示安装成功。

3.插件 FireBug
FireBug 是火狐浏览器的一款查看代码元素的插件,可以快速的定位元素,selenium的重点就是元素定位,只有定到位了,才能进行下一步操作。
安装方法:
--打开Firefox浏览器,点击右上角按钮
--点击附加组件
--点击扩展
--搜索firebug
--点击安装,重启浏览器
--测试安装成功,按F12出现如下画面,表示firebug已经安装成功了


4.安装 驱动安装 geckodriver(windows环境下)
文件链接在下方。
使用方法:
1、下载完成解压;
2、将 geckodriver 放到 该浏览器可执行文件的路径下

3、添加到环境变量中

5. 设置 pycharm
先创建一个工程
打开 pycharm -> 打开 file -> 点击 setting -> 点击最右边的设置按钮

点击 add, 在 Virtualenv Environment 和 System Interpreter 并选定找到本文给的 python 运行文件夹,Location 是自己建立的工作文件夹,里面为空,参考操作如下:

打开 pycharm -> 打开 file -> 点击 setting
将 project Interpreter 设置为 本文给的文件,或是自己本身的 python自带运行库

6. 新建一个python文件
输入以下程序:
# -*- coding: utf-8 -*- from selenium import webdriver driver = webdriver.Firefox() driver.get(https://www.baidu.com)
得到如下:

则成功搭建好环境。
7. 淘宝秒杀程序
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 2018/09/05
# 淘宝秒杀脚本,扫码登录版
import os
from selenium import webdriver
import datetime
import time
from os import path
from selenium.webdriver.common.action_chains import ActionChains
d = path.dirname(__file__)
abspath = path.abspath(d)
driver = webdriver.Firefox()
driver.maximize_window()
def login():
# 打开淘宝登录页,并进行扫码登录
driver.get("https://www.taobao.com")
time.sleep(3)
if driver.find_element_by_link_text("亲,请登录"):
driver.find_element_by_link_text("亲,请登录").click()
print("请在30秒内完成扫码")
time.sleep(30)
driver.get("https://cart.taobao.com/cart.htm")
time.sleep(3)
# 点击购物车里全选按钮
# if driver.find_element_by_id("J_CheckBox_939775250537"):
# driver.find_element_by_id("J_CheckBox_939775250537").click()
# if driver.find_element_by_id("J_CheckBox_939558169627"):
# driver.find_element_by_id("J_CheckBox_939558169627").click()
if driver.find_element_by_id("J_SelectAll1"):
driver.find_element_by_id("J_SelectAll1").click()
now = datetime.datetime.now()
print('login success:', now.strftime('%Y-%m-%d %H:%M:%S'))
def buy(buytime):
while True:
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# 对比时间,时间到的话就点击结算
if now > buytime:
try:
# 点击结算按钮
if driver.find_element_by_id("J_Go"):
driver.find_element_by_id("J_Go").click()
driver.find_element_by_link_text('提交订单').click()
except:
time.sleep(0.1)
print(now)
time.sleep(0.1)
if __name__ == "__main__":
# times = input("请输入抢购时间:")
# 时间格式:"2018-09-06 11:20:00.000000"
login()
buy("2018-10-22 18:55:00.000000")
以上程序是参照对应的 html 源码的对应元素所选择的。举例如下:

中对应的 J_SelectAll1 对应如下:

关于 selenium 和 html 源码的交互以后有时间再来研究。
资料链接如下:链接地址
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。