python爬取cnvd漏洞库信息的实例
今天一同事需要整理http://ics.cnvd.org.cn/工控漏洞库里面的信息,一看960多个要整理到什么时候才结束。
所以我决定写个爬虫帮他抓取数据。
看了一下各类信息还是很规则的,感觉应该很好写。
but这个网站设置了各种反爬虫手段。
经过各种百度,还是解决问题了。
设计思路:
1.先抓取每一个漏洞信息对应的网页url
2.获取每个页面的漏洞信息
# -*- coding: utf-8 -*-
import requests
import re
import xlwt
import time
from bs4 import BeautifulSoup
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36'
}
cookies={'__jsluid':'8d3f4c75f437ca82cdfad85c0f4f7c25'}
myfile=xlwt.Workbook()
wtable=myfile.add_sheet(u"信息",cell_overwrite_ok=True)
j = 0
a = 900
for i in range(4):
url ="http://ics.cnvd.org.cn/?max=20&offset="+str(a)
r = requests.get(urttp://ics.cnvd.org.cnl,headers=headers,cookies=cookies)
print r.status_code
while r.status_code != 200:
r = requests.get(url,headers=headers,cookies=cookies)
print r.status_code
html = r.text
soup = BeautifulSoup(html)
#print html
for tag in soup.find('tbody',id='tr').find_all('a',href=re.compile('http://www.cnvd.org.cn/flaw/show')):
print tag.attrs['href']
wtable.write(j,0,tag.attrs['href'])
j += 1
a += 20
print u"已完成%s"%(a)
filename=str(time.strftime('%Y%m%d%H%M%S',time.localtime()))+"url.xls"
myfile.save(filename)
print u"完成%s的url备份"%time.strftime('%Y%m%d%H%M%S',time.localtime())
# -*- coding: utf-8 -*-
from selenium import webdriver
import xlrd
import xlwt
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
class Gk(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(5)
self.verificationErrors = []
self.accept_next_alert = True
def test_gk(self):
myfile=xlwt.Workbook()
wtable=myfile.add_sheet(u"info",cell_overwrite_ok=True)
data = xlrd.open_workbook('url.xlsx')
table = data.sheets()[0]
nrows = table.nrows
driver = self.driver
j = 0
for i in range(nrows):
try:
s = []
driver.get(table.cell(i,0).value)
title = driver.find_element_by_xpath("//h1").text
print title
s.append(title)
trs = driver.find_element_by_xpath("//tbody").find_elements_by_tag_name('tr')
for td in trs:
tds = td.find_elements_by_tag_name("td")
for tt in tds:
print tt.text
s.append(tt.text)
k = 0
for info in s:
wtable.write(j,k,info)
k += 1
j += 1
except:
filename=str(time.strftime('%Y%m%d%H%M%S',time.localtime()))+"url.xls"
myfile.save(filename)
print u"异常自动保存%s的漏洞信息备份"%time.strftime('%Y%m%d%H%M%S',time.localtime())
filename=str(time.strftime('%Y%m%d%H%M%S',time.localtime()))+"url.xls"
myfile.save(filename)
print u"完成%s的漏洞信息备份"%time.strftime('%Y%m%d%H%M%S',time.localtime())
def is_element_present(self, how, what):
try: self.driver.find_element(by=how, value=what)
except NoSuchElementException, e: return False
return True
def is_alert_present(self):
try: self.driver.switch_to_alert()
except NoAlertPresentException, e: return False
return True
def close_alert_and_get_its_text(self):
try:
alert = self.driver.switch_to_alert()
alert_text = alert.text
if self.accept_next_alert:
alert.accept()
else:
alert.dismiss()
return alert_text
finally: self.accept_next_alert = True
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
好了。看看结果怎样!
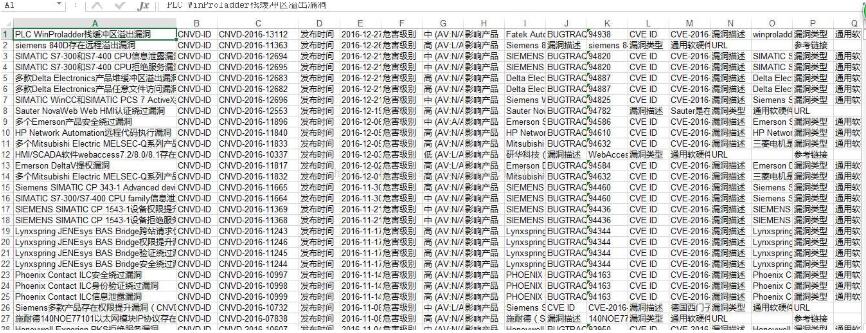
OK!剩下手动整理一下,收工!
以上这篇python爬取cnvd漏洞库信息的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。