15行Python代码实现网易云热门歌单实例教程
0. 引言
马上314情人节就要来了,是否需要一首歌来抚慰你,受伤或躁动的心灵。来吧,今天教你用15行代码搞定热门歌单。学起来并听起来吧。
本文使用的是Selenium模块,它是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等等操作,对于一些 JavaScript 渲染的页面来说,此种抓取方式非常有效。另外采用了Chrome浏览器配合Selenium工作。
下面话不多说了,来一起看看详细的介绍吧
1. 环境
操作系统:Windows
Python版本:3.7.2
2. 准备工作
a. 若你的环境中没有selenium模块,直接使用pip安装即可。
pip install selenium
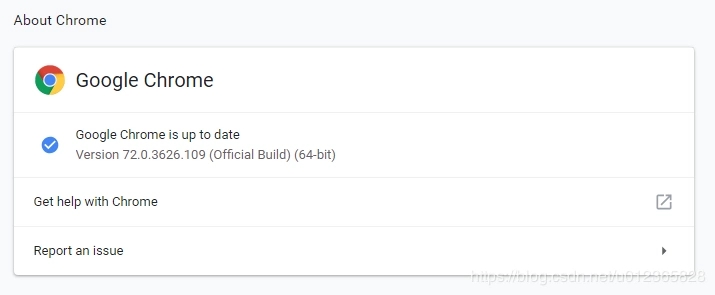
b. 打开谷歌浏览器,检查Chrome的版本:在浏览器地址中输入 chrome://settings/help 回车即可看到。
c. 打开ChromeDriver 的官方网站:
https://sites.google.com/a/ch...
寻找与你当前浏览器版本相对应的ChromeDriver下载。
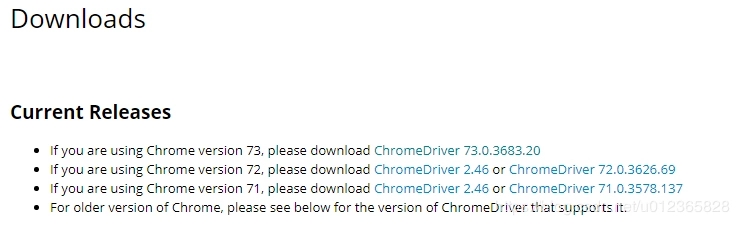
d. 选择你自己的操作系统类型进行下载即可。
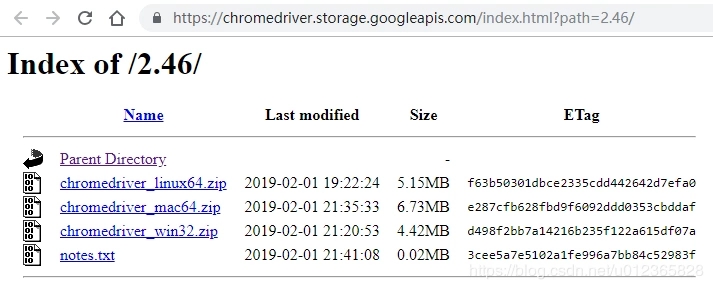
e. 以Windows为例,下载结束后,将ChromeDriver 放置在python安装目录下的Scripts文件夹即可。
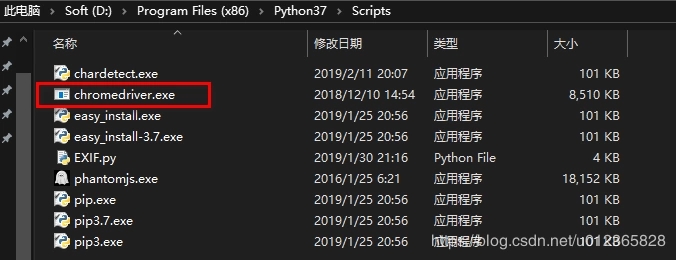
准备工作完成,代码写起来吧~
3. 迷你爬虫的实现
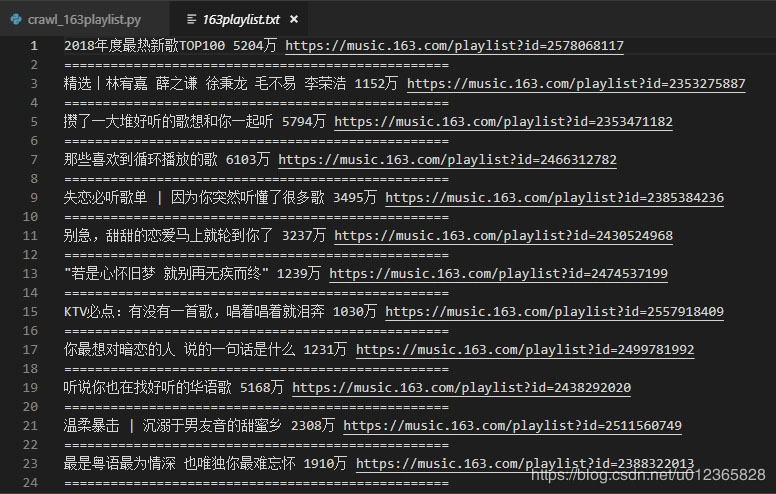
我们这次的目标是爬取热门歌单,比如网易云音乐中播放量大于1000万的歌单信息(歌单名称、链接)。
a. 我们先来打开网易云的歌单第一页:
https://music.163.com/#/disco...
b. 使用Chrome的开发者工具<F12>进行分析。
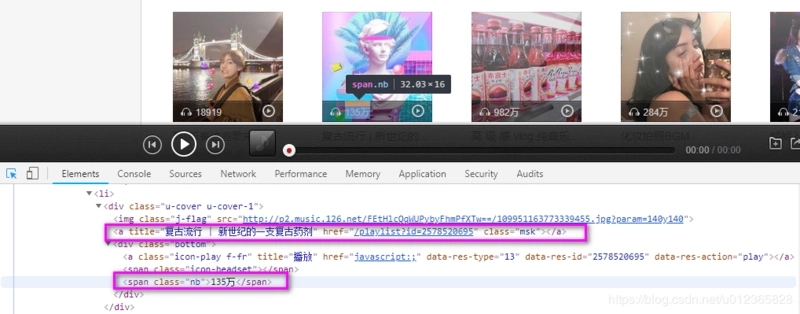
我们想要拿的信息全在这里:
- msk,封面[mask]:有歌单的名称及链接
- nb,播放数[number broadcast]:135万
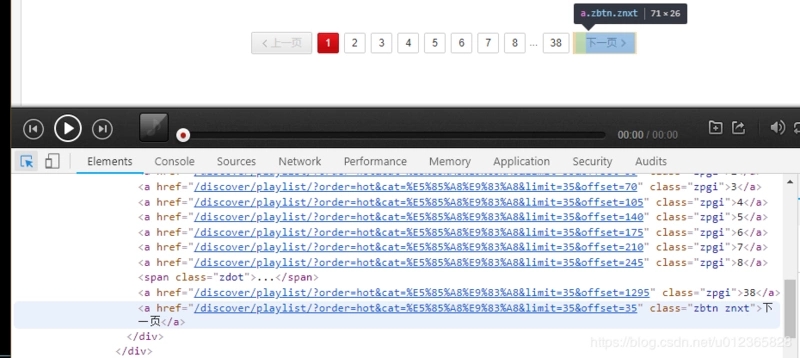
c. 我们还需要遍历所有的页,使用工具继续分析,找到“下一页”的URL。
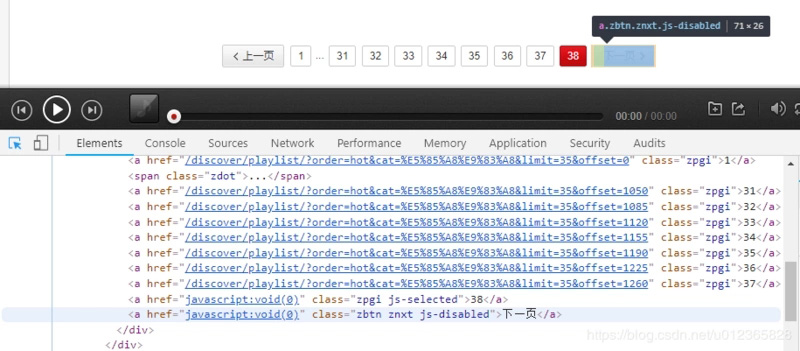
d. 切换至最后一页,拿到最后一页的URL。
e. 等我们爬取完所有符合的歌单信息后,将其保存在本地。
f. 全部工作结束,最后再通过下面的伪代码回顾下整体思路。

g. 爬取的效果如下:
4. 总结
本文旨在安抚你因情人节受伤的小心灵,同时带你入个爬虫的门,感受下python的强大。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。