Python这样操作能存储100多万行的xlsx文件
(1) 如果excel文件是xls,2003版的,使用xlrd和xlwt库来对xls文件进行操作
(2) 如果excel文件是xlsx,2007以上版的,使用openpyxl库来对xlsx文件进行操作
Tips:xlrd、xlwt和openpyxl非python自带库。
我们使用Python做数据挖掘和分析时候,当数据行超过一定数量,xls文件是存不下的。显然无法满足我们的大量数据存储需求,这个时候需要改用xlsx。
那具体xls和xlsx最大分别可以存多少行呢?
(1) 对于2003版本的xls文件,最大行数是65536行
(2) 对于2007版本的xlsx文件,最大行数是1048576行
闲话不多聊,直接上代码干货
!/usr/bin/env python3 - - coding: utf-8 - -
读写2007 excel
import pprint import openpyxl import openpyxl.styles from openpyxl.styles import Font,colors
读取Excel文件
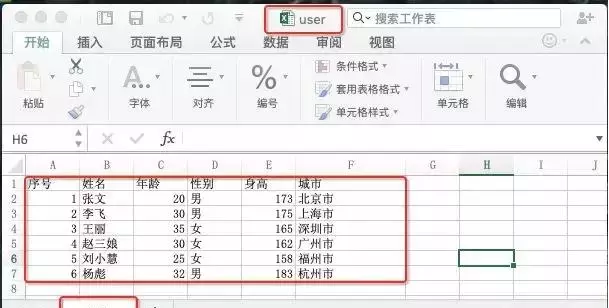
def readExcel(filename): workbook = openpyxl.load_workbook(filename) worksheet = workbook['用户'] list = [] for row in worksheet.rows: # 1行1行读 lineData = [] # 行数据 col = 1 for cell in row: lineData.append(cell.value) # 1列1列读 col = col + 1 list.append(lineData) return list
操作数据
def operateData(filename): list = readExcel(filename)
去除第一行,第一行是表头
list.pop(0)
pprint.pprint(list)
pprint.pprint("先按性别排序,再按身高排序")
要对身高进行排序,但是男女有别
先按性别排序,再按身高排序
list.sort(key=lambda ele: (ele[3], ele[4])) pprint.pprint(list)
获取Excel标签列表
比如第5行标签列表,总共4列 ['A5', 'B5', 'C5', 'D5']
def getTagList(index, colNum): tagList = [] for i in range(0, colNum):
A的ascii码值65
tag = chr(65 + i) + str(index) tagList.append(tag) return tagList
写入Excel文件
def writeExcel(outputFilePath, list):
book = openpyxl.Workbook()
sheet = book.create_sheet("用户", 0)
sheet.title = "用户" # sheet名称
rowNum = len(list)
try:
1行1行读取
for i in range(1, rowNum + 1): # 下标从1开始 datalist = list[i -1] # 读取1行 col = 1
1列1列写入
for data in datalist: sheet.cell(i, col, data) #写入内容 col += 1
获取标签列表
tagList = getTagList(i, len(datalist))
font = Font('微软雅黑', size = 14, color = '333333')
设置单元格字体、字号、颜色
for tag in tagList: sheet[tag].font = font # 设置字体
保存文件
book.save(outputFilePath) except Exception as e: # 捕获异常 print(e)
主函数
if name == " main ":
print("读取xlsx格式的数据")
userList = readExcel('user.xlsx')
print("写入xlsx文件")
writeExcel("user2.xlsx", userList)
print("操作数据")
operateData('user.xlsx')
总结
以上所述是小编给大家介绍的Python这样操作能存储100多万行的xlsx文件,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!