基于python实现百度翻译功能
运行环境: python 3.6.0
今天处于练习的目的,就用 python 写了一个百度翻译,是如何做到的呢,其实呢就是拿到接口,通过这个接口去访问,不过中间确实是出现了点问题,不过都解决掉了
先晾图后晾代码
运行结果:
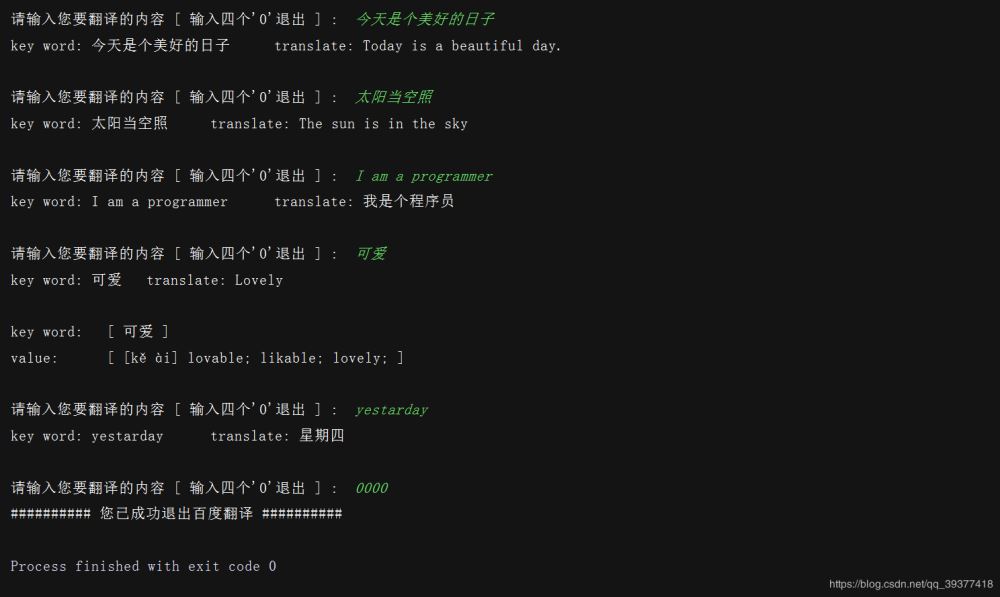
代码:
# -*- coding: utf-8 -*-
"""
功能:百度翻译
注意事项:中英文自动切换
"""
import requests
import re
class Baidu_Translate(object):
def __init__(self, query_string):
self.query_string = query_string
self.url_1 = 'https://fanyi.baidu.com/sug'
# self.url = 'https://fanyi.baidu.com/v2transapi' # 这里不能用这个地址,因为对方采用了反爬虫措施,访问这个地址是人家是不会给你任何数据的
self.url_0 = 'https://fanyi.baidu.com/transapi'
self.zh_pattern = re.compile('[\u4e00-\u9fa5]+')
self.headers = {
'Accept': '* / *',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN, zh; q=0.9',
'Connection': 'keep - alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_post_data(self):
"""
拿到 post 请求上传的参数,并判断输入类型并予以返回
:return: 查询词
"""
if re.search(pattern=self.zh_pattern, string=self.query_string): # 输入的内容含有中文,则判别其为中文输入
return {
"from": "zh",
"to": "en",
"kw": self.query_string, # 模糊查询 url_1关键词
"query": self.query_string, # 精准查询 url_0关键词
}
else:
return {
"from": "en",
"to": "zh",
"kw": self.query_string, # 模糊查询 url_1关键词
"query": self.query_string, # 精准查询 url_0关键词
}
def request_translate(self):
"""
向百度请求 json 数据
:return: 向百度请求的 json 数据
"""
data = self.get_post_data()
try:
response_0 = requests.request(method="post", url=self.url_0, headers=self.headers, data=data).json()
except Exception: # 进行数据请求的任何异常处理
response_0 = ''
try:
response_1 = requests.request(method="post", url=self.url_1, headers=self.headers, data=data).json()
except Exception: # 进行数据请求的任何异常处理
response_1 = ''
return response_0, response_1
def parse_translate_data(self):
"""
数据解析,将请求到的翻译内容解析并输出
:return: None
"""
response_0 = self.request_translate()[0]
response_1 = self.request_translate()[1]
# item = response_0
if response_0:
item = response_0.get('data')[0].get('dst')
print('key word:', self.query_string, '\t', 'translate:', item)
if response_1:
data = response_1.get('data')
print()
for item in data[:1]: # 长度一般为5,这里只保留其释义
print('key word: \t[ {key} ]'.format(key=item.get('k')))
print('value: \t\t[ {value} ]'.format(value=item.get('v')))
print()
# print(response_1.get('data'))
def main():
"""
主函数
:return: None
"""
while True:
try:
query_keywords = input("""请输入您要翻译的内容 [ 输入四个'0'退出 ] : """)
if query_keywords == "0000": # 如果输入四个 '0',退出小程序
print('########## 您已成功退出百度翻译 ##########')
break
else:
baidu = Baidu_Translate(query_string=query_keywords)
baidu.parse_translate_data()
except Exception as e:
print('请求出错,请重试', e.args)
if __name__ == '__main__':
main()
总结
以上所述是小编给大家介绍的基于python实现百度翻译功能,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
