详解Python字符串切片
在python中,我们定义好一个字符串,如下所示。

在python中定义个字符串然后把它赋值给一个变量。
我们可以通过下标访问单个的字符,跟所有的语言一样,下标从0开始(==,我自己都觉得写的好脑残了)
这个时候呢,我们可以通过切片的方式来截取出我们定义的字符串的一部分。
使用切片的时候我们有两种方式:
1.没有步长的简单切片
语法格式是这样的:
1.首先定义一格字符串,比如叫 Hebe,然后给它赋值
2. 截取字符串中的一部分,我们用的语法是 Hebe [ start : stop ]
注意一下: 在这里呢,start表示的是字符串要截取的开始下标,stop 表示终止的字符串结束的前一个位置,这个位置你可以理解为放的是反斜杠,那么显示出来的字符就是stop下标的前一位!!!前一位,前一位(重要的事情我们多说几遍!)
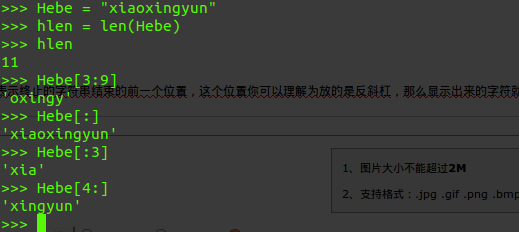
从上面这个图当中我们可以知道,如果从开头截取到某个特定的位置可以用 [ : a]来表示
>>> Hebe = "xiaoxingyun" >>> Hebe[:3] 'xia'
如果从某一位开始截取到最后一位可以用[ a : ]来表示
Hebe[4:] 'xingyun'
这里有一点要说明, 在 pyhton中的字符串的索引序号可以是正数也可以是负数,从-1开始算:
>>> Hebe = "xiaoxingyun" >>> Hebe[-1] 'n' >>> Hebe[-2] 'u' >>> Hebe[-3] 'y' >>> Hebe[-4] 'g'
所以我们还可以这么玩:
>>> Hebe[-3:] 'yun'
2.有步长的切片方式
另外的一种切片方式就是,首先还是定义一格字符串的变量,然后间隔的取出我们的字符串中的字符。
语法格式:
s [start: stop: stride]
同样这里取出来的字符串的结束字符是stop结束的前一个字符
stride表示的是间隔的取出字符串
下面来看几个例子:
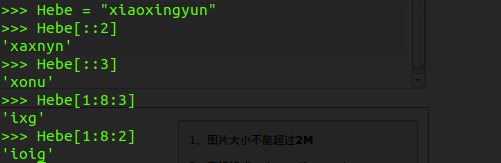
这个时候我们可以还可以反向的取出一格字符串
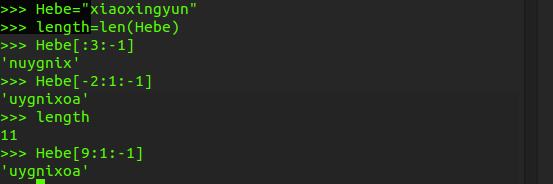
>>> Hebe="xiaoxingyun" >>> length=len(Hebe) >>> Hebe[::-1] 'nuygnixoaix' >>>
间隔逆向的取出一格字符串:
>>> Hebe[::-2] 'nynxax'
方向的截取部分的字符串:
这个时候我们将步长的那个地方设置为负数,表示从右向左取字符串,步长的绝对值大于1表示间隔的取数
开始的部分那个截取下标也要从负数计算,或者start必须大于结束的下标,因为它是从右开始的截取的
python的字符串就是这个样子的。
以上所述是小编给大家介绍的Python字符串切片详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!