在Pandas中处理NaN值的方法
关于NaN值
-在能够使用大型数据集训练学习算法之前,我们通常需要先清理数据, 也就是说,我们需要通过某个方法检测并更正数据中的错误。
- 任何给定数据集可能会出现各种糟糕的数据,例如离群值或不正确的值,但是我们几乎始终会遇到的糟糕数据类型是缺少值。
- Pandas 会为缺少的值分配 NaN 值。
创建一个具有NaN值得 Data Frame
import pandas as pd
# We create a list of Python dictionaries
# 创建一个字典列表
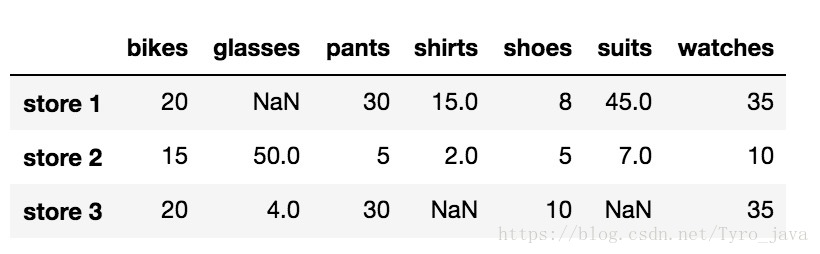
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes':8, 'suits':45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5, 'shirts': 2, 'shoes':5, 'suits':7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes':10}]
# 创建一个DataFrame并设置行索引
store_items = pd.DataFrame(items2, index = ['store 1', 'store 2', 'store 3'])
# 显示
store_items
显示:
数据量大时统计NaN的个数
# 计算在store_items中NaN值的个数
x = store_items.isnull().sum().sum()
# 输出
print('在我们DataFrame中NaN的数量:', x)
输出:
在我们DataFrame中NaN的数量: 3
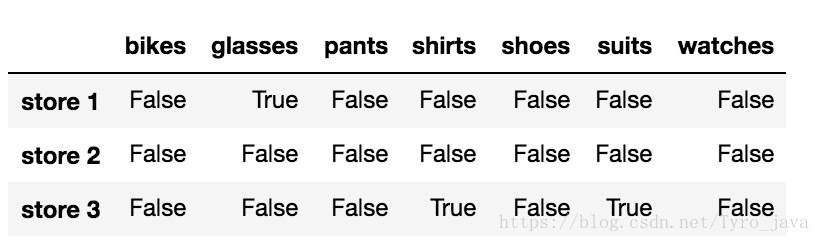
.isnull() 方法返回一个大小和 store_items 一样的布尔型 DataFrame,并用 True 表示具有 NaN 值的元素,用 False 表示非 NaN 值的元素。
store_items.isnull()
显示:
在 Pandas 中,逻辑值 True 的数字值是 1,逻辑值 False 的数字值是 0。
因此,我们可以通过数逻辑值 True 的数量数出 NaN 值的数量。
为了数逻辑值 True 的总数,我们使用 .sum() 方法两次。
要使用该方法两次,是因为第一个 sum() 返回一个 Pandas Series,其中存储了列上的逻辑值 True 的总数
第二个 sum() 将上述 Pandas Series 中的 1 相加
除了数 NaN 值的数量之外,我们还可以采用相反的方式,我们可以数非 NaN 值的数量。为此,我们可以使用 .count() 方法
print('在我们DataFrame的列中具有非NaN值得数量分别为:\n', store_items.count())
输出:
在我们DataFrame的列中具有非NaN值得数量:
bikes 3
glasses 2
pants 3
shirts 2
shoes 3
suits 2
watches 3
dtype: int64
处理这些 NaN 值
- 如果 axis = 0,.dropna(axis) 方法将删除包含 NaN 值的任何行
- 如果 axis = 1,.dropna(axis) 方法将删除包含 NaN 值的任何列
# 删除包含NaN值得任何行 store_items.dropna(axis = 0)
显示为:

store_items.dropna(axis = 1)
显示为:
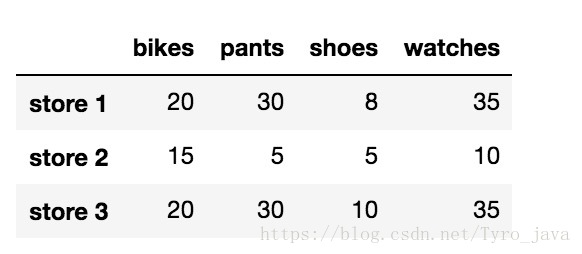
注意:
- .dropna() 方法不在原地地删除具有 NaN 值的行或列。
- 原始 DataFrame 不会改变。你始终可以在 dropna() 方法中将关键字 inplace 设为 True,在原地删除目标行或列。
将NaN值替换为合适的值
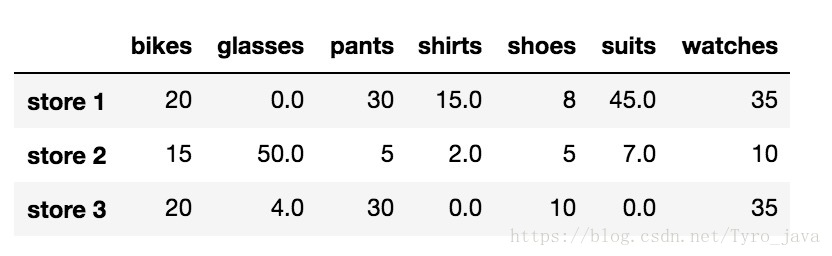
我们不再删除 NaN 值,而是将它们替换为合适的值。例如,我们可以选择将所有 NaN 值替换为 0。为此,我们可以使用 .fillna() 方法
store_items.fillna(0)
显示:
我们还可以使用 .fillna() 方法将 NaN 值替换为 DataFrame 中的上个值,称之为前向填充
.fillna(method = 'ffill', axis) 将通过前向填充 (ffill) 方法沿着给定 axis 使用上个已知值替换 NaN 值
store_items.fillna(method = 'ffill', axis = 0)
显示:
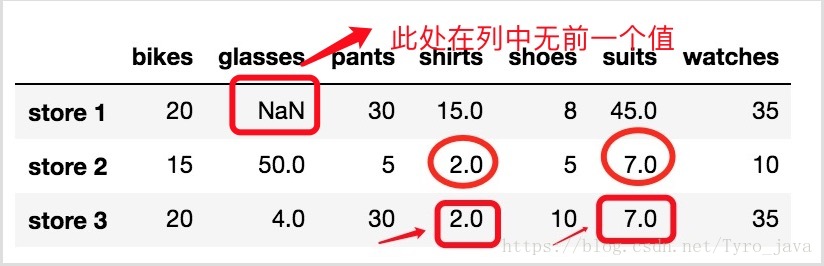
注意 store 3 中的两个 NaN 值被替换成了它们所在列中的上个值。
但是注意, store 1 中的 NaN 值没有被替换掉。因为这列前面没有值,因为 NaN 值是该列的第一个值。
现在,使用上个行值进行前向填充
store_items.fillna(method = 'ffill', axis = 1)
显示:
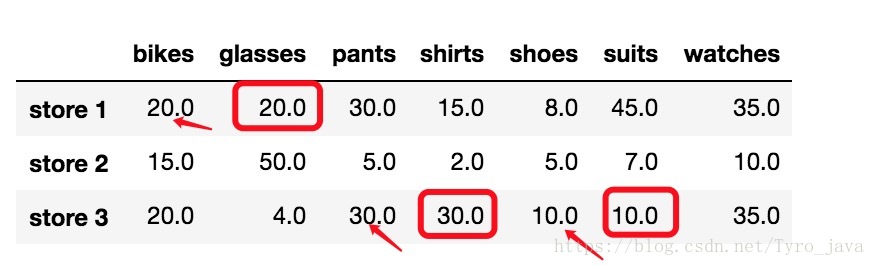
在这种情况下:所有 NaN 值都被替换成了之前的行值
同时,也可以选择用 DataFrame 中之后的值替换 NaN 值,称之为后向填充
# 向后填充列,即为NaN的列值,用其列中的后一个来填充 store_items.fillna(method = 'backfill', axis = 0)
同理:也可以向后填充行,即为NaN的行值,用其行中的后一个来填充
# 向后填充行,即为NaN的行值,用其行中的后一个来填充 store_items.fillna(method = 'backfill', axis = 1)
注意:.fillna() 方法不在原地地替换(填充)NaN 值。也就是说,原始 DataFrame 不会改变。你始终可以在 fillna() 函数中将关键字 inplace 设为 True,在原地替换 NaN 值。
还可以选择使用不同的插值方法替换 NaN 值
.interpolate(method = 'linear', axis) 方法将通过 linear 插值使用沿着给定 axis 的值替换 NaN 值, 这个差值也就是前后或者上下的中间值
store_items.interpolate(method = 'linear', axis = 0)
同时,也可用行值插入
store_items.interpolate(method = 'linear', axis = 1)
和我们看到的其他方法一样,.interpolate() 方法不在原地地替换 NaN 值,图片就省略了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。