使用Python做垃圾分类的原理及实例代码附源码
0 引言
纸巾再湿也是干垃圾?瓜子皮再干也是湿垃圾??最近大家都被垃圾分类折磨的不行,傻傻的你是否拎得清?😭😭😭自2019.07.01开始,上海已率先实施垃圾分类制度,违反规定的还会面临罚款。
为了避免巨额损失,我决定来b站学习下垃圾分类的技巧。为什么要来b站,听说这可是当下年轻人最流行的学习途径之一。
打开b站,搜索了下垃圾分类,上来就被这个标题吓(吸)到(引)了:在上海丢人的正确姿势。
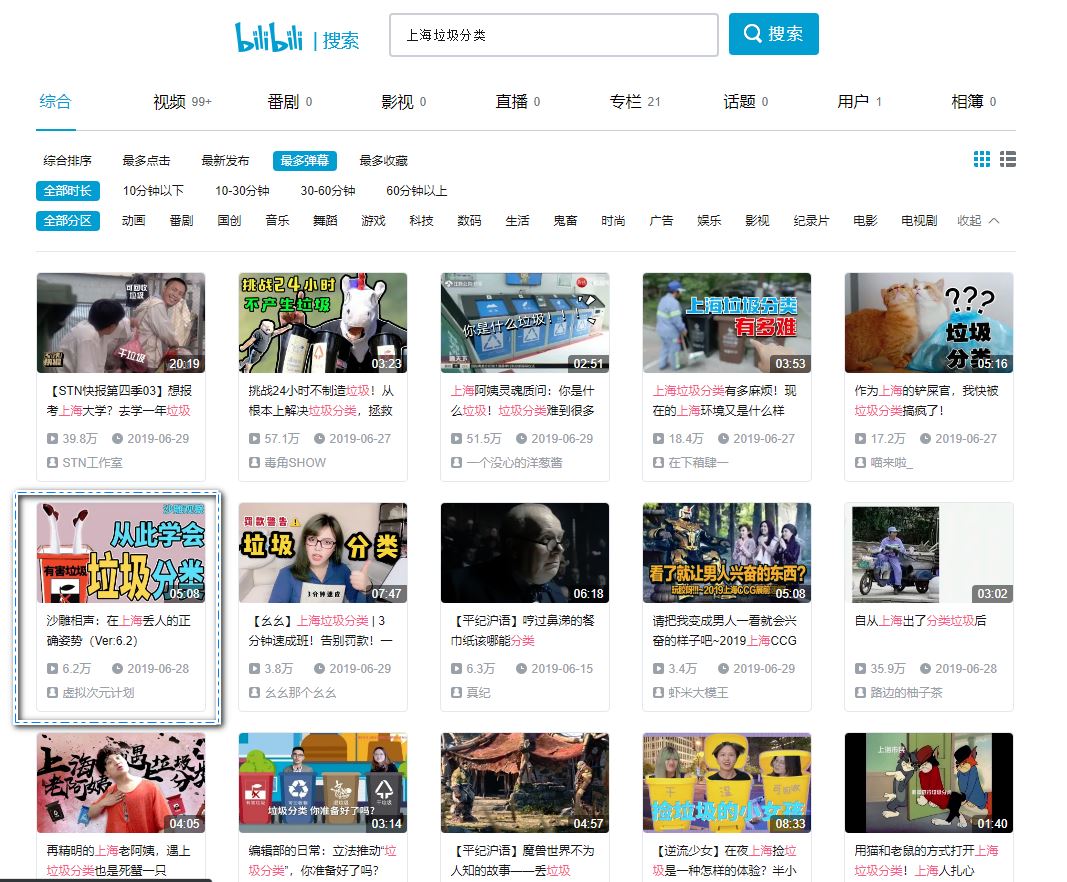
当然,这里的丢人非彼丢人,指的是丢垃圾的丢。
点开发现,原来是一段对口相声啊,还是两个萌妹子(AI)的对口相声,瞬间就来了兴趣,阐述的是关于如何进行垃圾分类的。



原视频链接:https://www.bilibili.com/video/av57129646?from=search&seid=9101123388170190749
看完一遍又一遍,简直停不下来了,已经开启了洗脑模式,毕竟视频很好玩,视频中的弹幕更是好玩!
独乐乐不如众乐乐,且不如用Python把弹幕保存下来,做个词云图?就这么愉快地决定了!
1 环境
操作系统:Windows
Python版本:3.7.3
2 需求分析
我们先需要通过
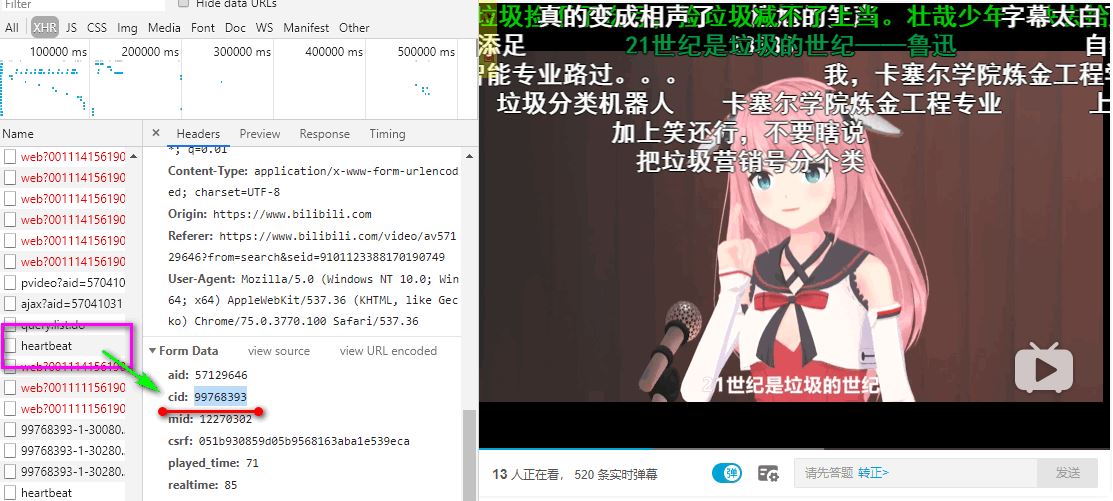
拿到 cid 之后,再填入下面的链接中。
http://comment.bilibili.com/{cid}.xml
打开之后,就可以看到该视频的弹幕列表。

有了弹幕数据后,我们需要先将解析好,并保存在本地,方便进一步的加工处理,如制成词云图进行展示。
3 代码实现
在这里,我们获取网页的请求使用 requests 模块;解析网址借助 beautifulsoup4 模块;保存为CSV数据,这里借用 pandas 模块。因为都是第三方模块,如环境中没有可以使用 pip 进行安装。
pip install requests pip install beautifulsoup4 pip install lxml pip install pandas
模块安装好之后,进行导入
import requests from bs4 import BeautifulSoup import pandas as pd
请求、解析、保存弹幕数据
# 请求弹幕数据
url = 'http://comment.bilibili.com/99768393.xml'
html = requests.get(url).content
# 解析弹幕数据
html_data = str(html, 'utf-8')
bs4 = BeautifulSoup(html_data, 'lxml')
results = bs4.find_all('d')
comments = [comment.text for comment in results]
comments_dict = {'comments': comments}
# 将弹幕数据保存在本地
br = pd.DataFrame(comments_dict)
br.to_csv('barrage.csv', encoding='utf-8')
接下来,我们就对保存好的弹幕数据进行深加工。
制作词云,我们需要用到 wordcloud 模块、matplotlib 模块、jieba 模块,同样都是第三方模块,直接用 pip 进行安装。
pip install wordcloud pip install matplotlib pip install jieba
模块安装好之后,进行导入,因为我们读取文件用到了 panda 模块,所以一并导入即可
from wordcloud import WordCloud, ImageColorGenerator import matplotlib.pyplot as plt import pandas as pd import jieba
我们可以自行选择一张图片,并基于此图片来生成一张定制的词云图。我们可以自定义一些词云样式,代码如下:
# 解析背景图片
mask_img = plt.imread('Bulb.jpg')
'''设置词云样式'''
wc = WordCloud(
# 设置字体
font_path='SIMYOU.TTF',
# 允许最大词汇量
max_words = 2000,
# 设置最大号字体大小
max_font_size = 80,
# 设置使用的背景图片
mask = mask_img,
# 设置输出的图片背景色
background_color=None, mode="RGBA",
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=30)
接下来,我们要读取文本信息(弹幕数据),进行分词并连接起来:
# 读取文件内容
br = pd.read_csv('barrage.csv', header=None)
# 进行分词,并用空格连起来
text = ''
for line in br[1]:
text += ' '.join(jieba.cut(line, cut_all=False))
最后来看看我们效果图

有没有感受到大家对垃圾分类这个话题的热情,莫名喜感涌上心头。
4 后记
这两个AI萌妹子说的相声很不错,就不知道郭德纲看到这个作品会作何感想。回到垃圾分类的话题,目前《上海市生活垃圾管理条例》已正式施行,不在上海的朋友们也不要太开心,住建部表示,全国其它46个重点城市也即将体验到……
源码,请点击此处。
以上所述是小编给大家介绍的使用Python做垃圾分类的原理及实例代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!