如何使用Python实现斐波那契数列
斐波那契数列(Fibonacci)最早由印度数学家Gopala提出,而第一个真正研究斐波那契数列的是意大利数学家 Leonardo Fibonacci,斐波那契数列的定义很简单,用数学函数可表示为:
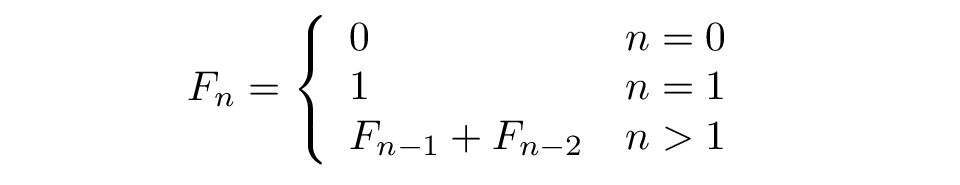
数列从0和1开始,之后的数由前两个数相加而得出,例如斐波那契数列的前10个数是:0, 1, 1, 2, 3, 5, 8, 13, 21, 34。
用 Python 实现斐波那契数列常见的写法有三种,各算法的执行效率也有很大差别,在面试中也会偶尔会被问到,通常面试的时候不是让你简单的用递归写写就完了,还会问你时间复杂度怎样,空间复杂度怎样,有没有可改进的地方。
递归法
所谓递归就是指函数的定义中使用了函数自身的方法
def fib_recur(n): assert n >= 0 if n in (0, 1): return n return fib_recur(n - 1) + fib_recur(n - 2) for i in range(20): print(fib_recur(i), end=" ") >>> 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
递归是一种代码最简洁的方法,但它是效率非常低,因为会出现大量的重复计算,时间复杂度是:O(1.618 ^ n),1.618是黄金分割。同时受限于 Python 中递归的最大深度是 1000,所以用递归来求解并不是一种可取的办法。
递推法
递推法就是从0和1开始,前两项相加逐个求出第3、第4个数,直到求出第n个数的值
def fib_loop(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a for i in range(20): print(fib_loop(i), end=" ") >>> 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
这种算法的时间复杂是O(n),呈线性增长,如果数据量巨大,速度越到后面会越慢。
上面两种方式都是使用分而治之的思想,就是把一个大的问题化小,然后利用小问题的求解得到目标问题的答案。
矩阵法
《线性代数》是大学计算机专业低年级的课程,这门课教的就是矩阵,那时候觉得这东西学起来很枯燥,没什么用处,工作后你才发现搞机器学习、数据分析、数据建模时大有用处,书到用时方恨少。其实矩阵的本质就是线性方程式。
斐波那契数列中两个相邻的项分别为:F(n) 和 F(n - 1),如果把这两个数当作一个2行1列的矩阵可表示为:
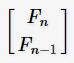
因为 F(n) = F(n-1)+F(n-2),所以就有:
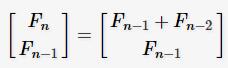
通过反推,其实它是两个矩阵的乘积得来的
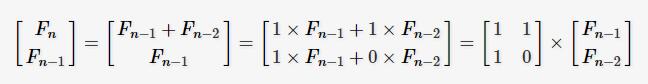
依此类推:
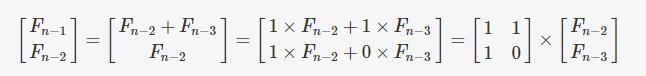
最后可推出:
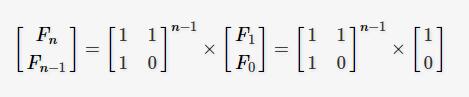
因此想要求出F(n)的值,只要能求出右边矩阵的n-1次方的值,最后求得两矩阵乘积,取新矩阵的第一行的第一列的值即可,比如n=3时,
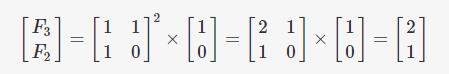
可以得知F(3)的值2,F(2)的值为1,因为幂运算可以使用二分加速,所以矩阵法的时间复杂度为 O(log n)
我们可以用科学计算包 numpy 来实现矩阵法:
import numpy def fib_matr(n): return (numpy.matrix([[1, 1], [1, 0]]) ** (n - 1) * numpy.matrix([[1], [0]]))[0, 0] for i in range(20): print(int(fib_matr(i)), end=" ") >>> 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
3中不同的算法效率对比:
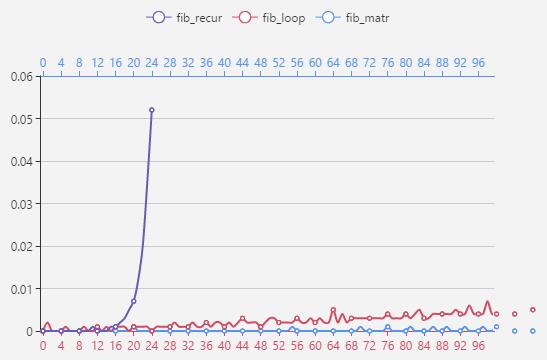
从上面图可以看出递归法效率惊人的低,矩阵法在数据量比较大的时候才突显出它的优势,递推法随着数据的变大,所花的时间也越来越大。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。