pandas实现to_sql将DataFrame保存到数据库中
目的
在数据分析时,我们有中间结果,或者最终的结果,需要保存到数据库中;或者我们有一个中间的结果,如果放到数据库中通过sql操作会更加的直观,处理后再将结果读取到DataFrame中。这两个场景,就需要用到DataFrame的to_sql操作。
具体的操作
连接数据库代码
import pandas as pd
from sqlalchemy import create_engine
# default
engine = create_engine('mysql+pymysql://ledao:ledao123@localhost/pandas_learn')
original_data = pd.read_sql_table('cellfee', engine)
original_data
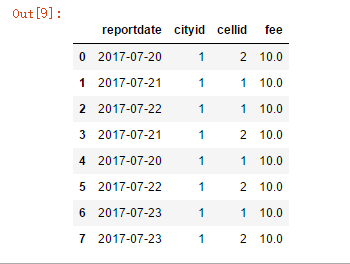
结果如下所示。
对数据进行汇总,每个小区的电费进行求和放到Series中,然后将所有小区的总电费放到DataFrame中,最后将DataFrame保存到数据库中,代码如下所示。
all_cells = [] for k, v in original_data.groupby(by=['cityid', 'cellid']): onecell = pd.Series(data=[k[0], k[1], v['fee'].sum()], index=['cityid', 'cellid', 'fee_sum']) all_cells.append(onecell) all_cells = pd.DataFrame(all_cells) all_cells.to_sql(name='cells_fee', con=engine, chunksize=1000, if_exists='replace', index=None)
对于DataFrame的to_sql函数,需要注意的参数在代码中已经写出来,其中比较重要的是chunksize、if_exists和index。
chunksize可以设置一次入库的大小;if_exists设置如果数据库中存在同名表怎么办,‘replace'表示将表原来数据删除放入当前数据;‘append'表示追加;‘fail'则表示将抛出异常,结束操作,默认是‘fail';index=接受boolean值,表示是否将DataFrame的index也作为表的列存储。
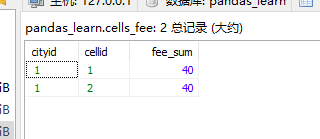
最终存表的结果如下图所示。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。