python爬虫之快速对js内容进行破解
前言
一般js破解有两种方法,一种是用Python重写js逻辑,一种是利用第三方库来调用js内容获取结果。这两种方法各有利弊,第一种方法性能好,但对js和Python要求掌握比较高;第二种方法快捷便利,对一些复杂js加密很有效。这次我们就用第三方库来进行js破解。
目标网站
本次网站是[企名片],网站对展示的数据进行了加密,所以直接找根本找不到。
目标url:https://www.qimingpian.com/finosda/project/pinvestment
js分析调试工具
对js进行分析调试的浏览器一定要用谷歌浏览器,用这个来调试测试真的很方便。首先我们按F12打开开发者工具,选到network选项并勾选preserve log 选项,然后输入网址url来抓包。此时你会发现网页源码里没有展示内容,在搜索也找不到我们看到的内容,那说明网页内容是被加密处理了。
此时你可以一个个看每个包找找有什么可疑的内容,当然我们一般会先看xhr里的内容,一眼我们就发现里面都有encrypt_data这个数据,看着很像。
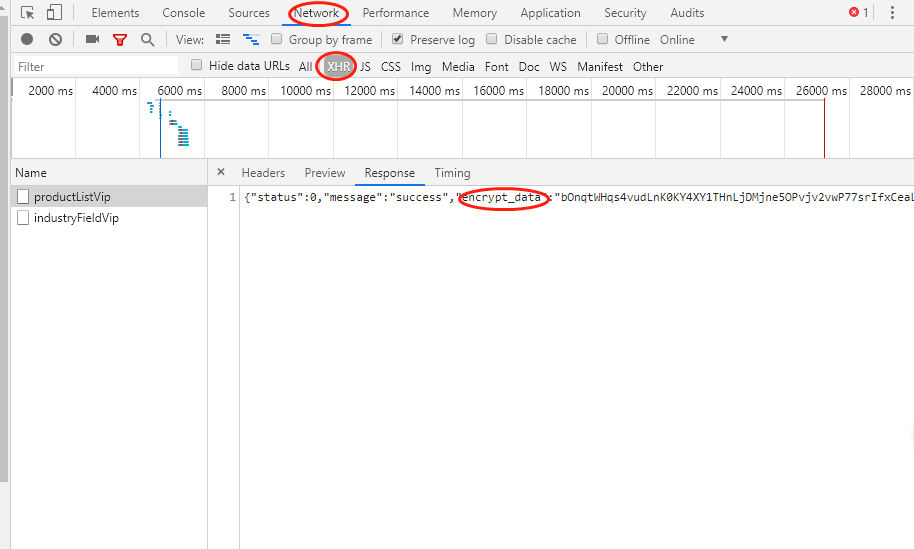
我们ctrl加shift加f键搜索encrypt_data,找到第一个js里的encrypt_data内容,然后翻到下面return e.encrypt_data这一行来,打上断点看看这会是什么内容。(一般我们搜索到return我们搜索的内容都要打上断点来看看,八九不离十的)
打好断点后我们刷新页面来观察,选中e.encrypt_data右键有个什么什么in console的,点这个会在下面出现我们选中的内容是什么。然后把后面的Object(d.a)(e.encrypt_data)用同样的方法来试下,发现没有网页的内容啊。
这里一定要注意我们打的断点,在按一次,重复上面的步骤会发现,Object(d.a)(e.encrypt_data)这不就是我们要的内容吗!e.encrypt_data这个就是我们xhr里面的那个encrypt_data,Object(d.a)是一个函数,就是这个函数对内容进行了加密,我们只要破解这个函数就OK了。
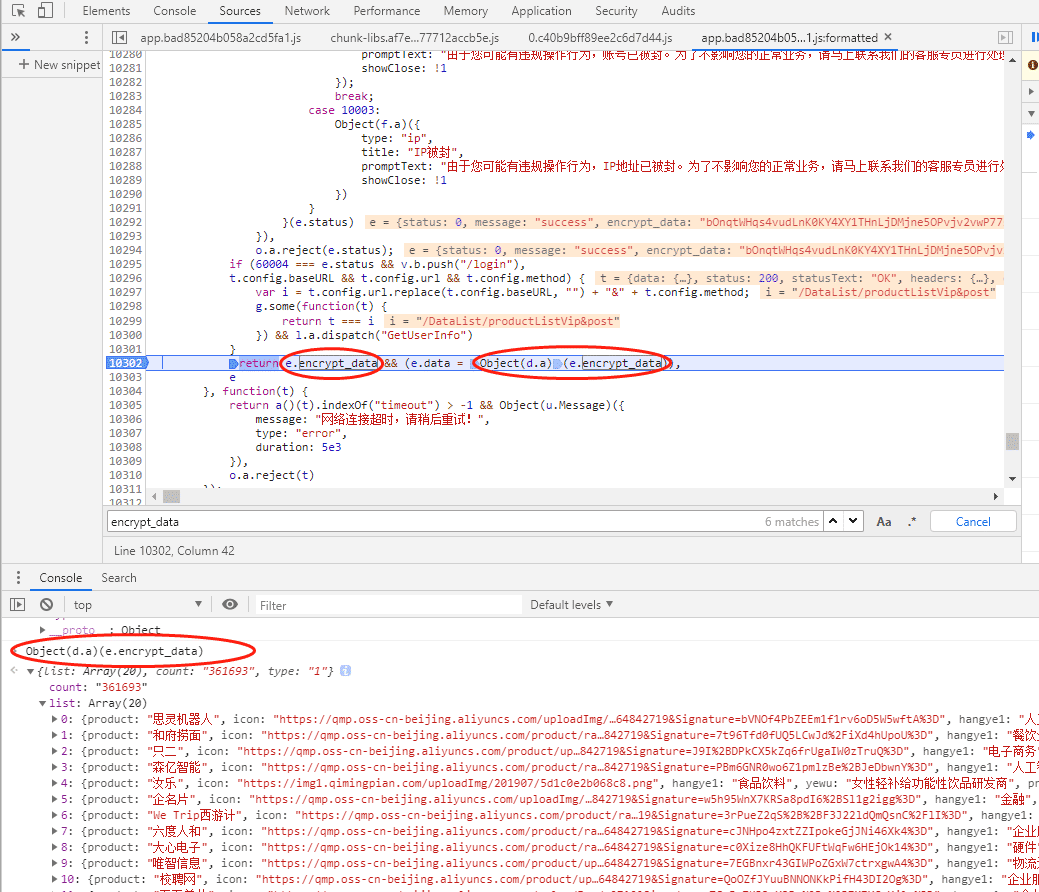
选中Object(d.a)上面会出现它在哪里,点击下跳转过去。可以发现函数返回了一个json对象。这个返回结果包括1个s函数,参数里只有a.a.decode(t)这一个变量,其余都是常量。

所有我们用同样的方法找到s函数的具体内容和a.a.decode()这个函数的具体内容。方法就是我们在return JSON.parse这里重新打断点,点击断点的那个下一步,然后找上述函数的内容。

s函数
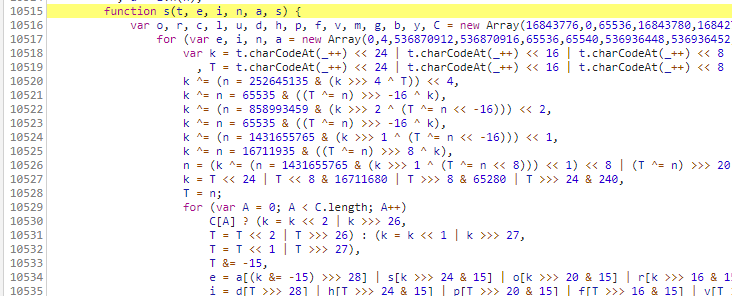
a.a.decode()

利用webstorm编辑器来运行上述函数进行调试
1 首先我们安装Nodejs,去官网下载安装,这是js环境。这个自己搜索个安装教程吧,这里不过多介绍了。
2 WebStorm 安装后激活,教程网上很多,大家自行搜索。它使用方式与 PyCharm 很类似。
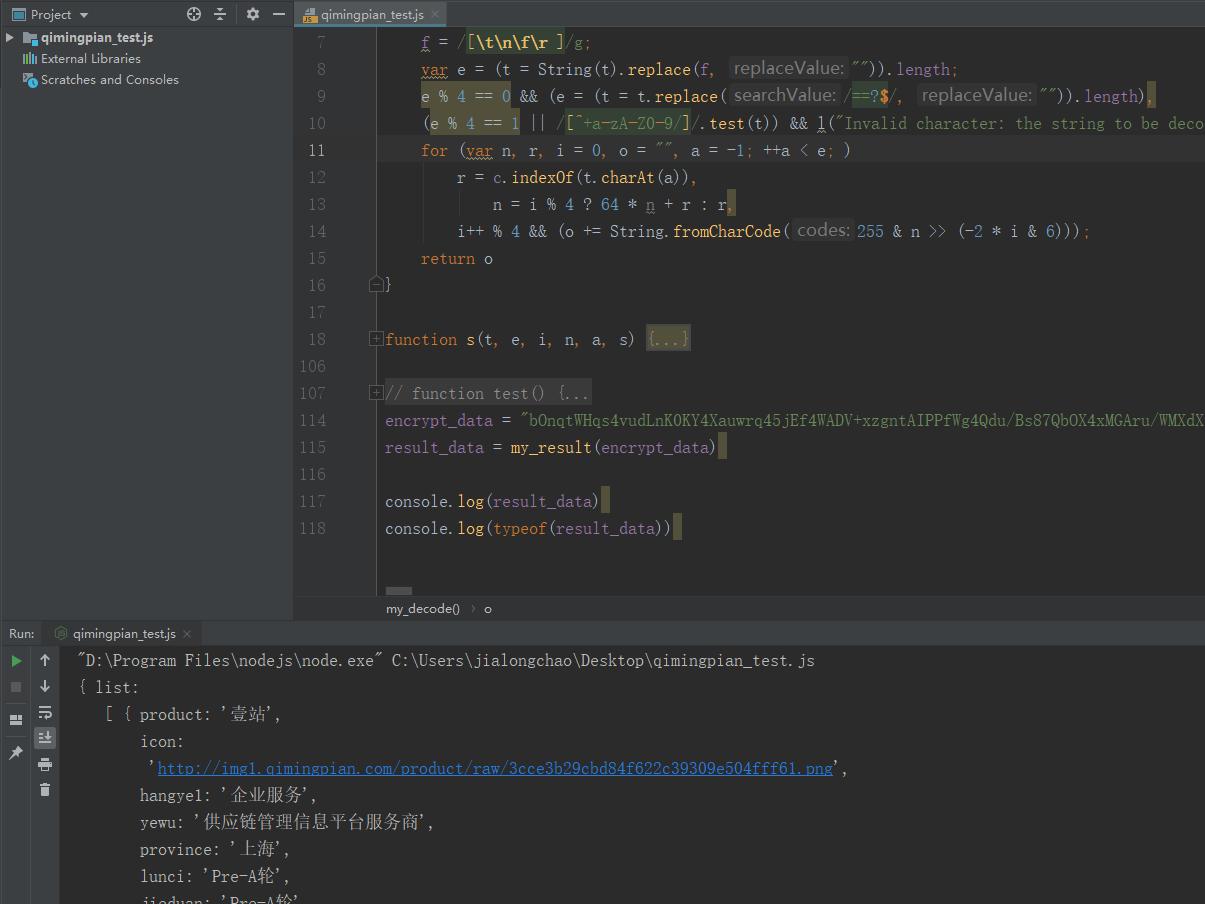
我们把上述所需要的函数全部扣下来放到webstorm中,然后运行。注意有的函数里面会有没有定义的参数,遇到这些我们几句在谷歌浏览器里一个个找就可以了,一般会有很多常量,直接替换掉。
然后我们调用上述方法可以看到能够正常获取数据了,这里js里的部分方法我重新命名了,注意下,下面是部分代码片段。
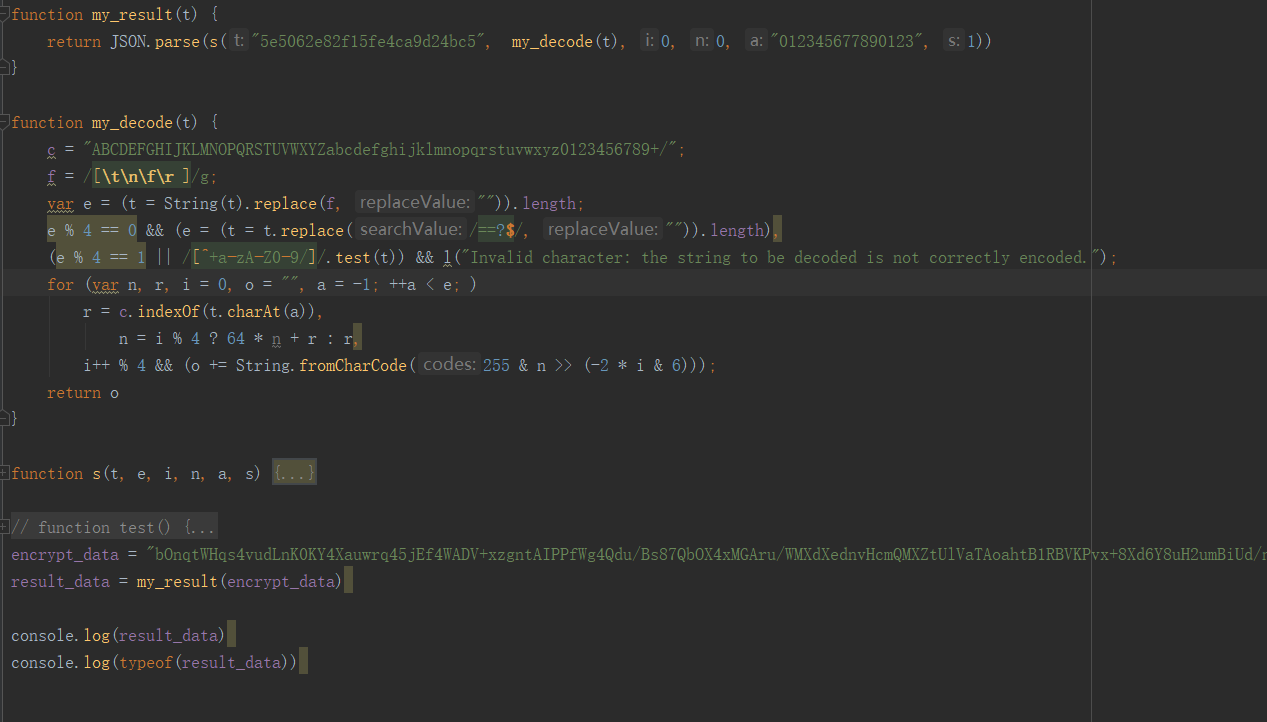
最后用 Python 去调用解密函数就行了,这里出于对网站保护就不直接贴完整代码了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
